Intro to Machine Learning I#
Basic Principles of Machine Learning#
Apa itu machine learning?#
Machine learning adalah cabang dari kecerdasan buatan (artificial intelligence) yang memungkinkan komputer untuk belajar dari data tanpa diprogram secara eksplisit. Algoritma machine learning memungkinkan sistem untuk meningkatkan kinerjanya seiring waktu dengan mengidentifikasi pola dan membuat prediksi berdasarkan data pelatihan.
Apa perbedaan antara supervised learning dan unsupervised learning?#
Supervised learning adalah jenis machine learning di mana model belajar dari data yang memiliki label/target yang benar. Sementara itu, unsupervised learning melibatkan data tanpa label, dan model harus mengidentifikasi pola dan struktur dalam data tersebut sendiri.
Apa itu evaluasi model dalam Machine Learning?#
Evaluasi model melibatkan penggunaan metrik untuk mengukur sejauh mana model dapat melakukan prediksi dengan benar pada data yang belum pernah dilihat sebelumnya. Evaluasi membantu memahami seberapa baik model bekerja dan apakah model memenuhi tujuan yang diinginkan.
Apa itu overfitting dan bagaimana mengatasinya?#
Overfitting terjadi ketika model machine learning terlalu kompleks sehingga dapat “menghafal” data pelatihan dan tidak dapat melakukan generalisasi dengan baik pada data baru. Untuk mengatasi overfitting, beberapa pendekatan yang dapat digunakan termasuk: mengurangi kompleksitas model, menggunakan teknik regularisasi, dan meningkatkan jumlah data pelatihan.
Apa perbedaan antara regresi dan klasifikasi dalam machine learning?#
Regresi digunakan untuk memprediksi nilai kontinu, seperti harga rumah atau suhu, sementara klasifikasi digunakan untuk memprediksi kategori diskrit, seperti jenis bunga atau apakah email adalah spam atau bukan.
Apa itu deep learning?#
Deep learning adalah cabang dari machine learning yang menggunakan neural networks dengan banyak lapisan (deep neural networks) untuk melakukan representasi dan ekstraksi fitur dari data secara otomatis. Deep learning telah membawa kemajuan besar dalam banyak aplikasi seperti pengenalan wajah, pengenalan suara, pengenalan tulisan tangan, dan lainnya.
Apa tantangan umum dalam machine learning?#
Beberapa tantangan umum dalam machine learning termasuk kekurangan data pelatihan, pemilihan model yang tepat, overfitting, mengatasi data yang tidak seimbang, interpretabilitas model, dan waktu komputasi yang lama untuk pelatihan model yang kompleks.
Mengapa Machine Learning penting dalam dunia modern?#
Machine Learning penting karena dapat membantu mengambil keputusan berdasarkan data, memahami pola yang rumit, dan meningkatkan efisiensi dalam berbagai bidang seperti kesehatan, keuangan, otomotif, industri, dan banyak lagi.
Data and Data Components in scikit-learn#
Apa yang dimaksud dengan Data dalam konteks Machine Learning?#
Data dalam Machine Learning adalah kumpulan informasi atau contoh yang digunakan untuk melatih, menguji, dan mengevaluasi model. Data ini terdiri dari fitur (features) yang merepresentasikan atribut dari objek dan label (target) yang mewakili output yang diinginkan.
Apa saja jenis-jenis Data yang digunakan dalam Machine Learning?#
Jenis-jenis data dalam Machine Learning meliputi data terstruktur (seperti tabel dan database), data tidak terstruktur (seperti teks, gambar, dan audio), data berlabel (untuk supervised learning), dan data tak berlabel (untuk unsupervised learning).
Apa itu scikit-learn?#
scikit-learn adalah salah satu library populer di Python untuk Machine Learning. Ia menyediakan berbagai algoritma machine learning dan fungsi utilitas untuk pelatihan, evaluasi, dan penerapan model.
Data Preprocessing: Handling Numerical Data#
Apa itu data numerik dalam konteks Machine Learning?#
Data numerik adalah data yang berupa angka dan dapat diukur dalam bentuk kontinu atau diskrit. Contoh data numerik adalah tinggi, berat, suhu, dan usia.
Apa yang harus dilakukan jika terdapat data numerik yang hilang (missing values)?#
Jika ada data numerik yang hilang, Anda dapat memutuskan untuk menghapus baris yang memiliki nilai yang hilang atau mengisi nilai yang hilang dengan nilai rata-rata, median, atau nilai lain yang relevan.
Apa itu normalisasi (normalization) dalam Data Preprocessing?#
Normalisasi adalah proses mengubah skala data numerik menjadi rentang yang seragam, biasanya antara 0 dan 1, atau -1 dan 1. Ini membantu dalam menghindari masalah dengan algoritma yang sensitif terhadap perbedaan skala data.
Kapan sebaiknya kita menggunakan normalisasi dan kapan menggunakan standarisasi (standardization)?#
Gunakan normalisasi saat Anda ingin mengubah rentang data ke [0, 1], misalnya pada algoritma seperti Neural Networks dan K-Means. Gunakan standarisasi saat Anda ingin mentransformasi data menjadi distribusi normal dengan mean 0 dan standar deviasi 1, misalnya pada algoritma seperti Regresi Linear dan SVM.
Data Preprocessing: Handling Categorical Data#
Apa itu data kategorikal dalam konteks Machine Learning?#
Data kategorikal adalah data yang berisi kategori atau label yang tidak dapat diukur secara numerik. Contoh data kategorikal adalah jenis kelamin, jenis bunga, negara, dan warna.
Bagaimana cara mengatasi data kategorikal dalam Machine Learning?#
Ada beberapa pendekatan untuk mengatasi data kategorikal:
One-Hot Encoding: Mengubah setiap kategori menjadi vektor biner dengan nilai 0 atau 1.
Label Encoding: Menggantikan setiap kategori dengan nilai numerik secara berurutan.
Ordinal Encoding: Menggantikan kategori dengan nilai numerik sesuai dengan urutan yang sudah ditentukan.
Kapan sebaiknya kita menggunakan One-Hot Encoding dan kapan menggunakan Label Encoding?#
Gunakan One-Hot Encoding ketika kategori tidak memiliki hubungan ordinal (urutan) dan untuk algoritma yang tidak berbasis jarak. Gunakan Label Encoding ketika kategori memiliki hubungan ordinal atau untuk algoritma yang berbasis jarak seperti K-Nearest Neighbors (KNN).
Bagaimana cara mengatasi data kategorikal dengan banyak kategori unik?#
Jika ada data kategorikal dengan banyak kategori unik, Anda dapat mempertimbangkan untuk menggunakan teknik seperti Binary Encoding, Hashing Encoding, atau mengelompokkan beberapa kategori menjadi satu kategori yang lebih umum.
Bagaimana cara melakukan ordinal encoding dengan membuat list kategori yang sudah diurutkan?#
Ketika menghadapi suatu kolom kategori yang memiliki jumlah nilai unik yang banyak, akan sulit mengurutkannya secara langsung dengan menggunakan .cat.rename_categories() untuk proses pengubahan menjadi angka. Berikut adalah sebuah alternatif metode untuk memudahkan proses tersebut:
Definisikan sebuah list berisi seluruh nilai unik pada category yang sudah terurut dengan benar.
education = ['SD', 'SMP', 'SMA', 'S1', 'S2', 'S3']
Gunakan method
.cat.reorder_categories(list_order, ordered=True)untuk mengubah urutan dari category pada kolom yang ingin dilakukan ordinal encoding.employee['education'] = employee['education'].cat.reorder_categories(education, ordered=True)
Ubah setiap category menjadi angka dari 0 hingga jumlah category secara otomatis dengan menggunakan atribut
.cat.codesemployee['education'] = employee['education'].cat.codes
Train-test Splitting#
Apa itu Train-test Splitting dalam Machine Learning?#
Train-test Splitting adalah teknik di mana kita membagi dataset menjadi dua subset terpisah: data latih (train set) yang digunakan untuk melatih model, dan data uji (test set) yang digunakan untuk menguji kinerja model pada data yang belum pernah dilihat sebelumnya.
Mengapa kita perlu melakukan Train-test Splitting?#
Train-test Splitting penting untuk mengukur seberapa baik model machine learning dapat melakukan generalisasi pada data yang belum pernah dilihat sebelumnya. Dengan membagi data menjadi dua subset, kita dapat menghindari overfitting dan mendapatkan estimasi kinerja model yang lebih andal.
Berapa besar proporsi pembagian antara data latih dan data uji?#
Proporsi pembagian antara data latih dan data uji tergantung pada ukuran dataset dan karakteristik masalah. Secara umum, pembagian umum yang digunakan adalah 70%-80% data latih dan 20%-30% data uji.
Apakah Train-test Splitting dilakukan sekali saja?#
Idealnya, Train-test Splitting dilakukan beberapa kali untuk menghindari hasil yang bias. Dalam teknik validasi silang (cross-validation), dataset dibagi menjadi beberapa fold, dan proses pelatihan dan pengujian dilakukan secara berulang untuk setiap fold.
Bagaimana cara melakukan Train-test Splitting di Python?#
Dalam Python, kita dapat menggunakan library Scikit-learn untuk melakukan Train-test Splitting. Contoh penggunaannya:
from sklearn.model_selection import train_test_split
# X adalah matriks fitur, y adalah vektor target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Bagaimana cara train-test splitting pada kasus classification, agar proporsi tiap kategori target setara, baik pada data train maupun data test?#
Menggunakan stratified sampling dengan parameter stratify, contoh:
x_train, x_test, y_train, y_test = train_test_split(
x,
y,
test_size = 0.2, # 80% training and 20% test
random_state = 1,
stratify=y
)
Mengapa kita menggunakan random_state dalam Train-test Splitting?#
Penggunaan random_state dalam Train-test Splitting memastikan bahwa pembagian dataset dilakukan dengan cara yang sama setiap kali kode dijalankan. Ini membantu memastikan reproduktibilitas hasil dan membandingkan model dengan kondisi yang serupa.
Kapan Train-test Splitting sebaiknya digunakan?#
Train-test Splitting digunakan ketika kita ingin membagi dataset menjadi dua bagian: satu untuk melatih model dan satu untuk menguji model. Ini sangat berguna untuk mengukur kinerja model pada data yang belum pernah dilihat sebelumnya dan mengidentifikasi masalah seperti overfitting.
Apa itu random state, dan apa pengaruhnya saat kita menggunakan fungsi train_test_split() di scikit-learn?#
random_state adalah parameter yang digunakan dalam fungsi train_test_split di library scikit-learn untuk mengontrol pemilihan data acak saat membagi dataset menjadi subset pelatihan dan pengujian. Parameter ini memastikan bahwa pembagian data acak dapat direproduksi, sehingga hasilnya dapat konsisten antara berbagai eksekusi.
Ketika kita menggunakan train_test_split tanpa menyertakan nilai untuk random_state, pembagian dataset akan acak setiap kali fungsi tersebut dijalankan. Namun, jika kita menyertakan nilai tertentu untuk random_state, kita akan mendapatkan pembagian yang sama setiap kali kita menjalankan kode tersebut.
Pentingnya random_state terletak pada reproduksibilitas hasil eksperimen dan memastikan bahwa model yang dilatih pada dataset yang sama memberikan hasil yang sama setiap kali dijalankan. Hal ini berguna ketika kita ingin membandingkan model atau melakukan debugging.
Berapa nilai yang disarankan untuk random_state?#
Angka yang baik untuk random_state sebenarnya tidak memiliki nilai spesifik yang dianggap “baik”. Nilai tersebut dapat berupa angka apa pun, dan yang penting adalah nilai tersebut harus konsisten agar hasil dapat direproduksi. Banyak orang menggunakan angka seperti 0, 42, atau 2023, tetapi yang lebih penting adalah memilih satu nilai dan tetap konsisten dengan nilai tersebut selama eksperimen atau pemodelan. Pilihan nilai ini tidak mempengaruhi kualitas model, tetapi memastikan reproduksibilitas hasil.
Untuk splitting dataset training dan testing, apakah memang common yang 80:20 kemarin? Apakah ada kondisi split lain yang common digunakan?#
Terdapat beberapa teknik train-test split (cross-validation), namun apapun teknik yang digunakan, proporsi data train selalu lebih besar daripada data test
Holdout cross-validation
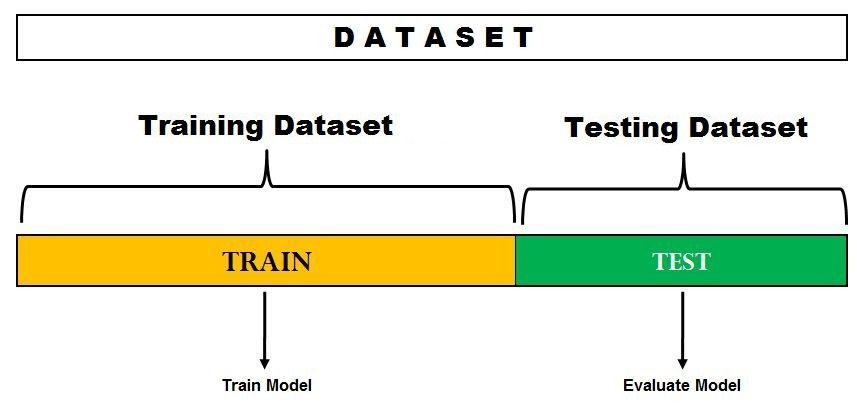
Teknik cross-val ini sama dengan yang dipelajari di kelas, yaitu memisahkan 70%-80% data menjadi data train, dan 20%-30% menjadi data test
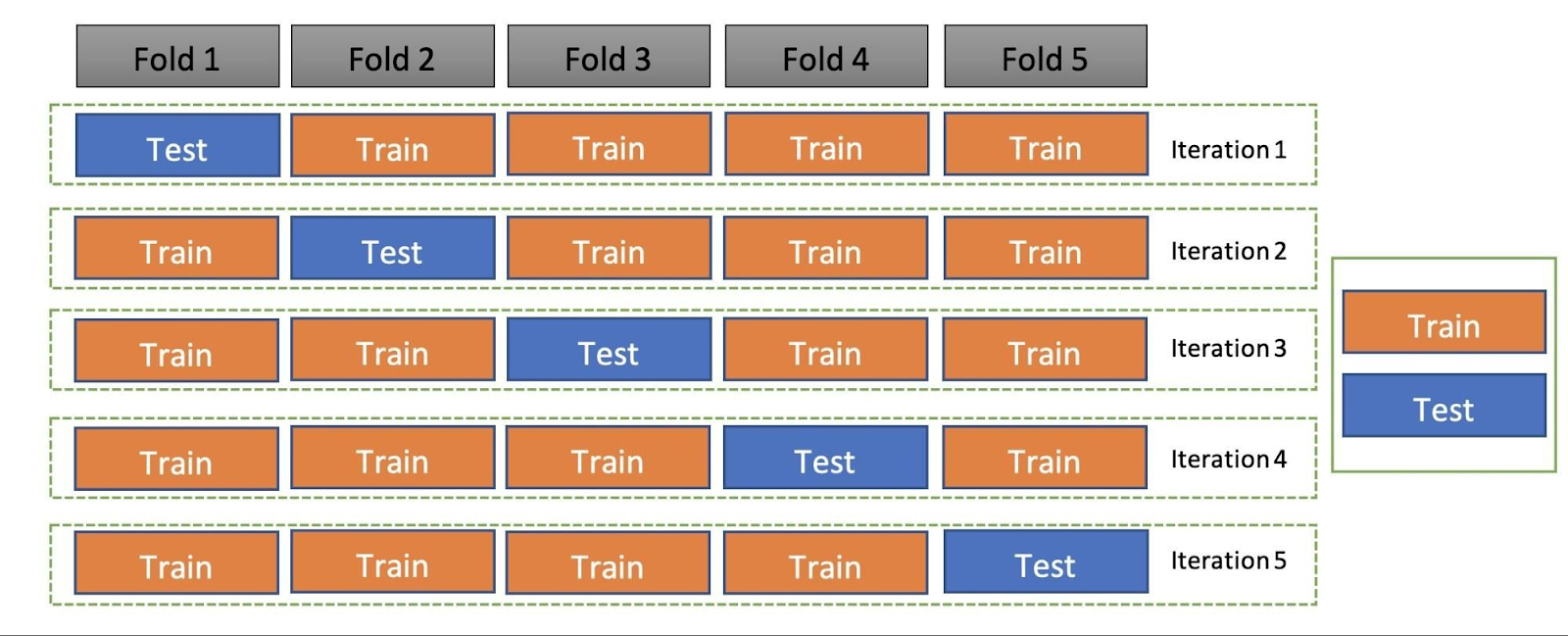
K-fold cross-validation Pada k-fold cross-val, data awal dibagi menjadi k bagian sama besar, kemudian salah satu bagian digunakan untuk data test, dan sisanya menjadi data train. Setelah itu, bagian-bagian ini akan digilir.
Leave-p-out cross-validation (LpOCV) & Leave-one-out cross-validation (LOOCV)
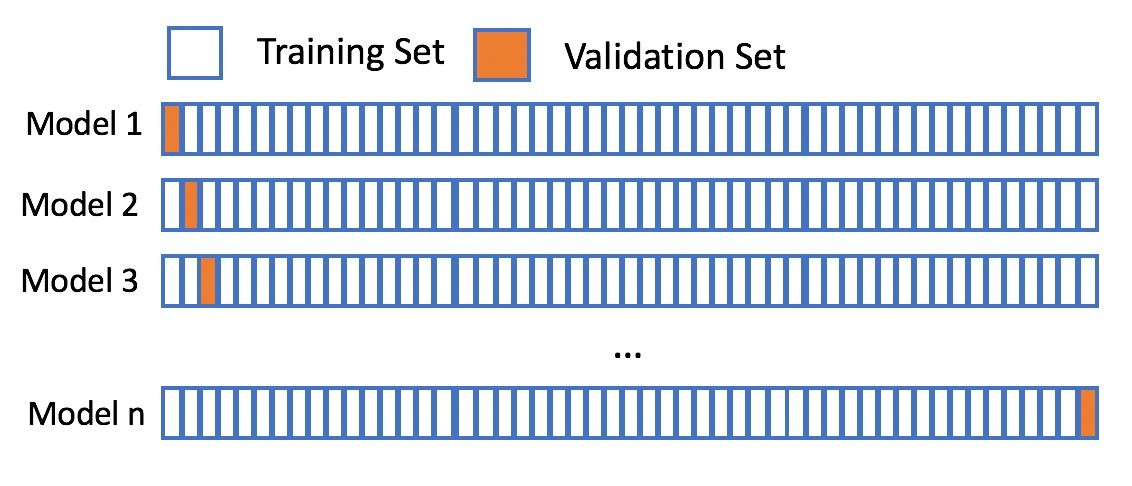
LpOCV serupa dengan k-fold, namun data yang digunakan untuk data test adalah sejumlah p baris data. Jika p = 1, maka metode ini disebut LOOCV
Repeated k-Fold cross-validation
Teknik cross-val ini sama dengan k-fold biasa, namun setelah 1 putaran, data diacak dan dilakukan k-fold & training kembali. Pengulangan ini dilakukan sebanyak n kali repeat.
Time-series cross-validation
Ketika bekerja dengan data time series, waktu menjadi hal yang krusial dan harus berurutan, oleh karena itu pada time series cross-val, data train harus merupakan data yang lebih lampau daripada data test.
Support Vector Machine (SVM):#
Apa itu Support Vector Machine (SVM)?#
Support Vector Machine (SVM) adalah algoritma machine learning yang digunakan untuk tugas klasifikasi dan regresi. SVM mencari garis atau permukaan pemisah optimal yang memaksimalkan margin (jarak) antara kelas atau target yang berbeda.
Apa yang dimaksud dengan margin dalam SVM?#
Margin dalam SVM adalah jarak antara garis pemisah (atau hiperplane) dan contoh data terdekat dari setiap kelas. SVM berusaha untuk memaksimalkan margin ini untuk meningkatkan kemampuan generalisasi model.
Bagaimana cara mengimplementasikan SVM dalam Python?#
Anda dapat menggunakan library Scikit-learn untuk mengimplementasikan SVM dalam Python. Misalnya, untuk klasifikasi, Anda bisa menggunakan SVC untuk SVM dengan kernel linier atau SVC dengan kernel non-linier seperti RBF. Untuk regresi, Anda bisa menggunakan SVR.
Apa itu kernel dalam SVM dan apa peranannya?#
Kernel adalah fungsi matematika yang digunakan untuk memetakan data ke dimensi yang lebih tinggi, di mana data dapat dipisahkan lebih baik. Kernel memungkinkan SVM untuk menangani masalah yang tidak linier, sehingga memungkinkan model untuk menemukan pemisah yang lebih kompleks.
Bagaimana SVM digunakan dalam tugas klasifikasi?#
SVM dapat digunakan untuk mengklasifikasikan data dengan mencari pemisah yang optimal antara kelas yang berbeda. SVM mencoba untuk menemukan hyperplane (garis jika 2 dimensi, permukaan dalam dimensi yang lebih tinggi) yang memaksimalkan margin antara kelas.
Apa yang dimaksud dengan C dalam SVM?#
C dalam SVM adalah parameter regulasi yang mengontrol penalti terhadap kesalahan klasifikasi. Nilai C yang lebih besar akan mengenakan penalti yang lebih tinggi pada kesalahan, yang dapat menyebabkan model lebih kompleks dan cenderung overfitting.
Bagaimana SVM digunakan dalam tugas regresi?#
SVM juga dapat digunakan dalam tugas regresi dengan menggunakan SVR. Tujuan dari SVM dalam regresi adalah untuk mencari garis atau permukaan yang memiliki jarak minimal dengan sebagian besar data, sehingga garis atau permukaan tersebut dapat menjadi model prediksi.
Apa yang dimaksud dengan epsilon dalam SVR?#
Epsilon dalam SVR adalah parameter yang mengontrol lebar “tube” di sekitar garis/regresi. Data yang jatuh di dalam tube tidak mendapatkan penalti, tetapi data di luar tube akan dikenai penalti berdasarkan besarnya perbedaan.
Model Evaluation#
Apa itu data uji (test set) dalam evaluasi model?#
Data uji adalah subset data yang tidak digunakan selama pelatihan model. Ini digunakan untuk menguji performa model pada data yang belum pernah dilihat sebelumnya, sehingga dapat mengukur kemampuan generalisasi model.
Apa itu Mean Absolute Error (MAE)?#
MAE adalah metrik alternatif untuk mengukur kesalahan prediksi pada regresi. MAE mengukur rata-rata dari selisih absolut antara nilai aktual dan nilai prediksi. Rumusnya adalah sebagai berikut:
$$ {\text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|} $$
Ini menghitung rata-rata perbedaan absolut antara nilai prediksi dan nilai sebenarnya. Semakin rendah nilai MAE, semakin baik kinerja model.
Apa itu Mean Absolute Percentage Error (MAPE)?#
MAPE adalah metrik yang mengukur rata-rata persentase dari kesalahan absolut relatif terhadap nilai aktual. Rumusnya adalah sebagai berikut:
$$ \text{MAPE} = \frac{1}{n} \sum_{i=1}^{n} \left| \frac{y_i - \hat{y}_i}{y_i} \right| \times 100% $$
Kapan suatu model/data cocok dengan metrics MAE atau MAPE untuk kasus regresi?#
Pemilihan metriks tentunya tergantung data dan tujuan analisis. Suatu situasi akan cocok dengan nilai MAE apabila sejumlah besar data dan beberapa nilai mendekati nol. Hal ini dikarenakan MAE mengukur kesalahan absolut tanpa memperhitungkan presentase kesalahan relatif seperti yang dilakukan MAPE. Jika kita menggunakan MAPE disaat data kita memiliki nilai yang mendekati nol, maka perhitungan presentase pada MAPE akan menjadi nilai yang sangat tinggi dan tidah realistis serta kemungkinan besar tidak mencerminkan performa model sesungguhnya.
Studi Kasus:
Dimisalkan kita memiliki 2 hasil evaluasi untuk 2 model yang berbeda
Model 1:
MAE: 500
MAPE : 10%
Model 2:
MAE : 300
MAPE : 15%
Kapan kondisi kita memilih Model 1 atau Model 2?
Model 1 (MAPE yang rendah): Apabila lebih memilih akurasi presentase kesalahan relatif terhadap nilai sebenarnya. Misalnya, jika ingin tahu seberapa besar kesalahan dalam presentase dari nilai yang sebenarnya
Model 2 (MAE yang rendah): Apabila lebih fokus pada kesalahan absolut dalam unit nilai yang sebenarnya. Misalnya, jika ingin tahu sberapa perbedaan rata-rata nilai yang diprediksi dan nilai sebenarnya dalam satuan yang sama, seperti rupiah, unit produk, dll.
Apa itu confusion matrix dan apa kegunaannya dalam evaluasi model klasifikasi?#
Confusion matrix juga sering disebut error matrix. Pada dasarnya confusion matrix memberikan informasi perbandingan hasil klasifikasi yang dilakukan oleh sistem (model) dengan hasil klasifikasi sebenarnya.
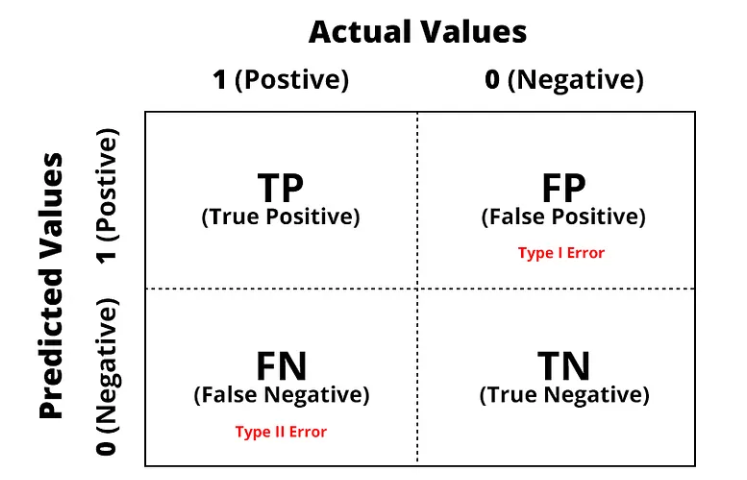
Confusion matrix adalah tabel yang digunakan untuk mengevaluasi kinerja model klasifikasi dengan membandingkan prediksi model dengan nilai sebenarnya.
Terdapat 4 istilah sebagai representasi hasil proses klasifikasi pada confusion matrix. Keempat istilah tersebut adalah True Positive (TP), True Negative (TN), False Positive (FP) dan False Negative (FN). Agar lebih mudah memahaminya, mari menggunakan contoh kasus sederhana untuk memprediksi seorang pasien menderita kanker atau tidak.
True Positive (TP)
Merupakan data positif yang diprediksi benar. Contohnya, pasien menderita kanker (class 1) dan dari model yang dibuat memprediksi pasien tersebut menderita kanker (class 1).
True Negative (TN)
Merupakan data negatif yang diprediksi benar. Contohnya, pasien tidak menderita kanker (class 2) dan dari model yang dibuat memprediksi pasien tersebut tidak menderita kanker (class 2).
False Postive (FP) — Type I Error
Merupakan data negatif namun diprediksi sebagai data positif. Contohnya, pasien tidak menderita kanker (class 2) tetapi dari model yang telah memprediksi pasien tersebut menderita kanker (class 1).
False Negative (FN) — Type II Error
Merupakan data positif namun diprediksi sebagai data negatif. Contohnya, pasien menderita kanker (class 1) tetapi dari model yang dibuat memprediksi pasien tersebut tidak menderita kanker (class 2).
Tips: Ada cara yang lebih mudah untuk mengingatnya, yaitu:
Jika diawali dengan True maka prediksinya adalah benar, baik diprediksi terjadi atau tidak terjadi.
Jika diawali dengan False maka prediksinya adalah salah.
Positif dan negatif merupakan hasil prediksi dari model.
Bagaimana mengukur performance metrics dari sebuah model klasifikasi dari confusion matrix ?#
Kita dapat menggunakan confusion matrix untuk menghitung berbagai performance metrics untuk mengukur kinerja model yang telah dibuat. Pada bagian ini mari kita pahami beberapa performance metrics populer yang umum dan sering digunakan: accuracy, precission, dan recall.
Apa itu Accuracy?#
Accuracy adalah metrik yang mengukur persentase prediksi benar dari semua prediksi yang dibuat oleh model klasifikasi. Maka, accuracy merupakan rasio prediksi benar (positif dan negatif) dengan keseluruhan data. Ini adalah ukuran dasar untuk mengukur kinerja model klasifikasi.
Namun, akurasi bisa menjadi bias jika data tidak seimbang (imbalanced).
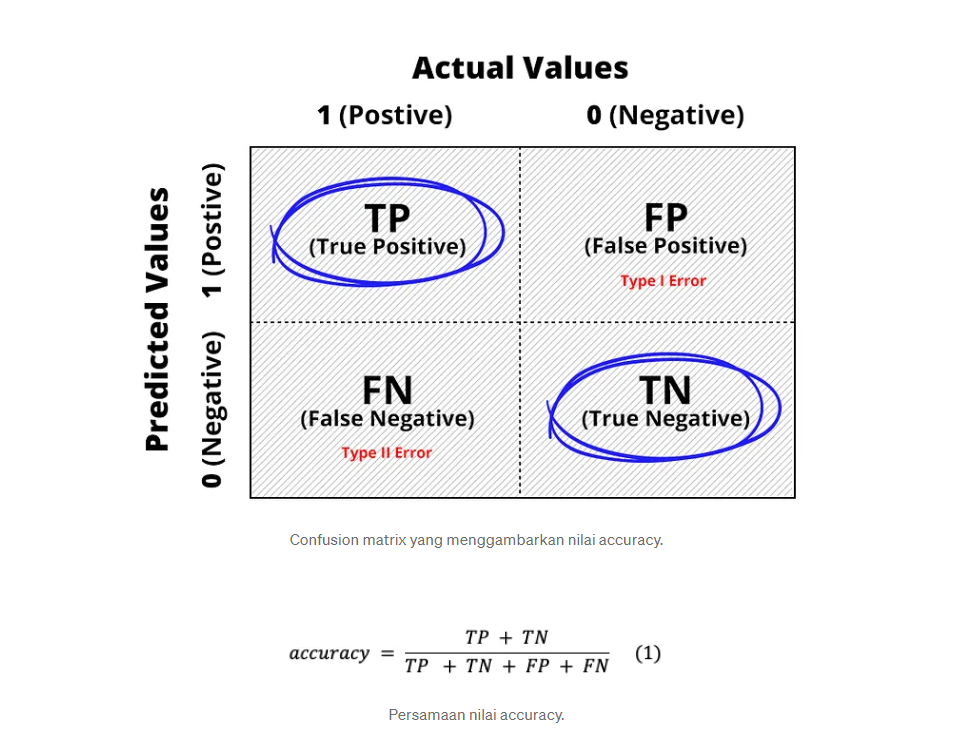
Bagaimana cara menghitung Akurasi?#
Akurasi dihitung dengan membagi jumlah prediksi benar (true positives dan true negatives) dengan jumlah total sampel.
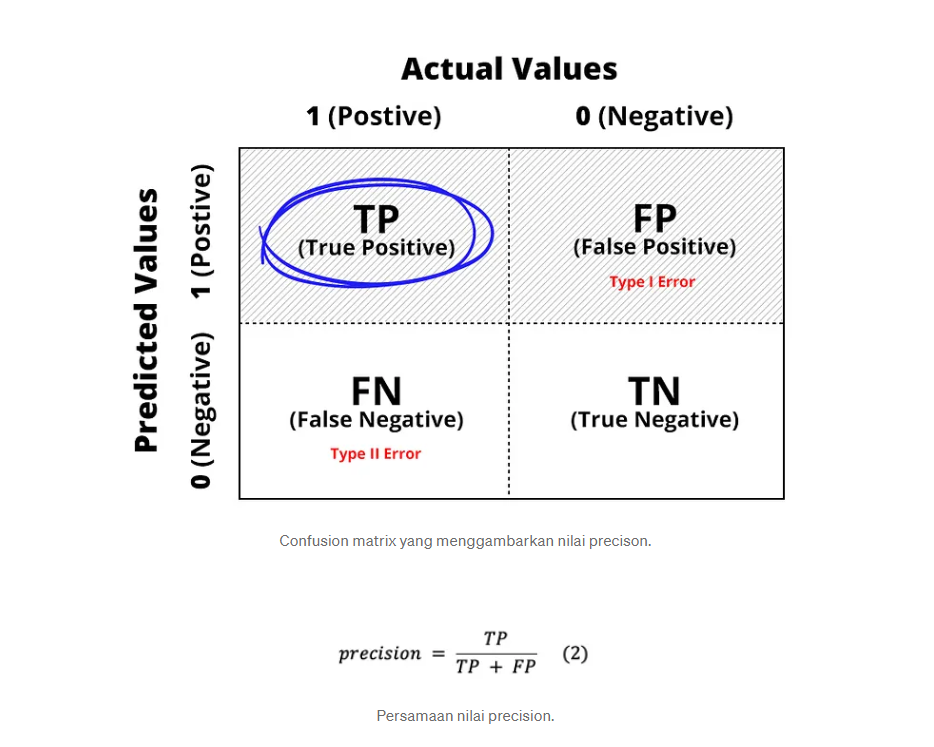
Apa itu Precision dan Recall?#
Precision dan recall adalah metrik yang digunakan untuk mengukur kinerja model klasifikasi pada kelas tertentu.
Precision mengukur persentase prediksi benar positif dari semua prediksi positif. Maka, precision merupakan rasio prediksi benar positif dibandingkan dengan keseluruhan hasil yang diprediksi positf. Dari semua kelas positif yang telah di prediksi dengan benar, berapa banyak data yang benar-benar positif.
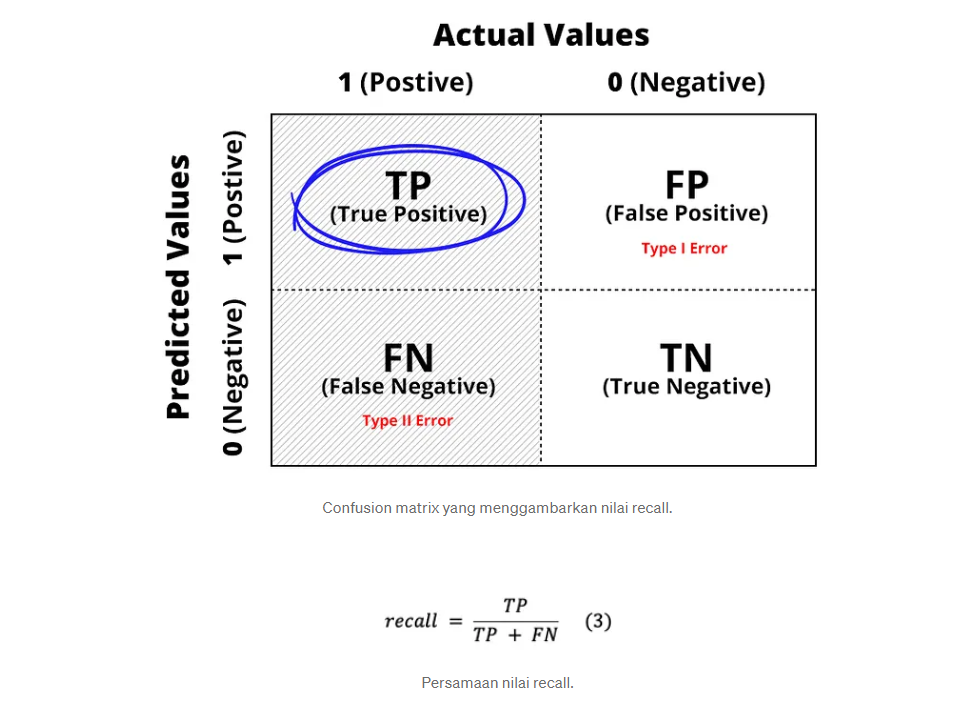
Sedangkan recall mengukur persentase kelas positif yang berhasil diidentifikasi oleh model dari semua kelas positif yang ada. Maka, recall merupakan rasio prediksi benar positif dibandingkan dengan keseluruhan data yang benar positif.
Apa perbedaan antara Precision dan Recall?#
Perbedaan utama antara precision dan recall adalah fokusnya. Precision fokus pada sejauh mana prediksi positif model benar, sedangkan recall fokus pada kemampuan model untuk menemukan semua kasus positif yang ada.
Apa itu F1-Score?#
F1-score adalah metrik yang menggabungkan precision dan recall menjadi satu nilai tunggal untuk mengukur kinerja model klasifikasi. Ini berguna ketika kelas-kelas yang dihadapi tidak seimbang.
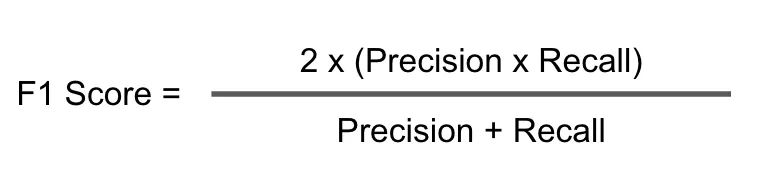
Bagaimana cara menghitung F1-Score?#
F1-Score dihitung sebagai rata-rata harmonis dari precision dan recall. Formulanya adalah 2 * (precision * recall) / (precision + recall).
Apa perbedaan F1-Score dengan Accuracy?#
Rangkuman rumus akurasi, presisi dan recall:

Dengan menggunakan akurasi, hanya membagi jumlah kejadian benar dengan total kejadian. Nah biasanya kita membutuhkan presisi dan juga recall untuk mendapatkan informasi yang lebih banyak oleh model kita. Biasanya kita menggunakan salah satunya saja, yaitu presisi atau recall.
Namun, bagaimana jika ingin mempertimbangkan presisi dan juga recall sekaligus? Di sinilah kita menggunakan F1 score dimana perhitungannya berdasarkan precision dan recall, sehingga F1 score merangkum lebih banyak informasi mengenai performa model kita dibandingkan akurasi, recall dan precison saja.
Namun, pada kasus klasifikasi, mengapa metric accuracy tidak selalu cukup menjelaskan seberapa baik model yang diperoleh?#
Untuk mengetahui seberapa baik perfomance model klasifikasi, tidak cukup dengan melihat nilai accuracy nya saja, karena accuracy menganggap sama penting untuk kasus False Positive (FP) dan False Negative (FN). Apabila kasus FP dan Kita membutuhkan metric lain seperti Precision dan Recall.
1️⃣ Contoh Pertama: pada kasus prediksi pasien apakah mengidap kanker jinak atau ganas. Tentunya akan lebih berbahaya apabila pasien dengan kanker ganas namun terprediksi menjadi jinak. Hal ini dapat membahayakan keselamatan pasien karena tidak ditangani dengan serius oleh pihak medis. Pada kasus ini ingin diminimalisir kasus terjadinya False Negative, maka kita mengharapkan nilai Recall yang lebih tinggi dibandingkan metric lainnya.
2️⃣ Contoh Kedua: pada kasus prediksi email apakah termasuk spam atau ham (tidak spam). Akan lebih berbahaya apabila email yang sebenarnya tidak spam namun terprediksi sebagai spam. Hal ini mengakibatkan email tidak spam akan masuk ke folder spam sehingga email penting tidak terbaca oleh pengguna. Pada kasus ini ingin diminimalisir kasus False Positive, maka kita mengharapkan nilai Precision yang tinggi dibandingkan metric lainnya.
Apabila kedua metric Recall dan Precision sama-sama ingin diharapkan tinggi, dapat menggunakan metric F1-score.
Model Improvement Technique#
Apa itu teknik pemrosesan data dan bagaimana itu dapat meningkatkan model?#
Teknik pemrosesan data melibatkan tahap pra-pemrosesan seperti penanganan data hilang, normalisasi, dan encoding. Ini dapat meningkatkan model dengan membersihkan data, menghindari masalah numerik, dan mengubah data ke format yang sesuai untuk model tertentu.
Bagaimana teknik pemilihan fitur (feature selection) dapat meningkatkan model?#
Teknik pemilihan fitur digunakan untuk memilih subset fitur yang paling relevan dan penting untuk meningkatkan kinerja model. Ini mengurangi dimensi data dan memperbaiki akurasi dan kecepatan model.
Apa itu teknik ensemble dan bagaimana cara kerjanya?#
Teknik ensemble adalah metode yang menggabungkan beberapa model machine learning untuk mencapai performa yang lebih baik. Contohnya adalah metode Voting, Bagging, dan Boosting.
Apa sebenarnya konsep hyperparameter tuning dari segi kalkulasi?#
Untuk cara kerja dan praktikal dari SVM dapat merujuk ke buku berikut pada halaman 115: Link Buku.
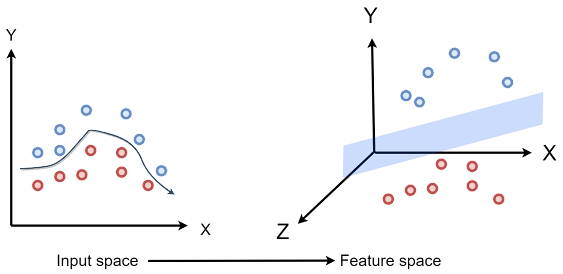
Adapun secara intuisi, untuk data non-linear, yang dilakukan SVM adalah mengubahnya menjadi dimensi yang lebih tinggi sehingga dapat dipisahkan oleh hyperplane yang linear. Seperti di bawah ini. Pada gambar di sebelah kiri, kelas biru dan kelas merah tidak bisa dibagi secara linear, namun diakali dengan mentransformasi ke dimensi yang lebih tinggi sehingga dapat terbentuk hyperplane yang membagi kelas biru dan kelas merah.
Transformasi ini dilakukan oleh kernel rbf (radial basis function).
Hyperparameters SVM#
Apa itu hyperparameter dalam SVM?#
Hyperparameter adalah parameter yang tidak dipelajari oleh model secara otomatis melalui proses pelatihan. Sebagai gantinya, mereka diatur sebelum pelatihan dan mempengaruhi kinerja model.
Apa peran parameter C dan gamma dalam SVM?#
Parameter C adalah hyperparameter yang mengontrol penalti untuk kesalahan klasifikasi pada model SVM. Nilai C yang lebih besar menyebabkan model lebih kompleks dan mungkin menyebabkan overfitting. Parameter gamma mengontrol berapa banyak pengaruh titik pelatihan yang jauh dari garis pemisah.
Bagaimana cara melakukan pemilihan hyperparameter yang optimal untuk SVM?#
Pemilihan hyperparameter dapat dilakukan dengan mencoba berbagai nilai melalui metode uji coba dan validasi silang (cross-validation). Anda dapat menggunakan teknik seperti Grid Search atau Random Search untuk menemukan kombinasi hyperparameter yang optimal.