SQL Query using pandas#
Database Schema#
Apa itu database schema?#
Database schema atau yang disebut sebagai Entity Relationship Diagram (ERD) merupakan suatu skema yang digunakan untuk merancang suatu basis data, ada tiga komponen utama di dalamnya:
Entitas: tabel pada sebuah database
Atribut: kolom beserta tipe datanya pada masing-masing tabel
Hubungan: relasi antar entitas beserta tipe hubungannya
Berikut adalah contoh database schema atau ERD untuk data chinook.db:
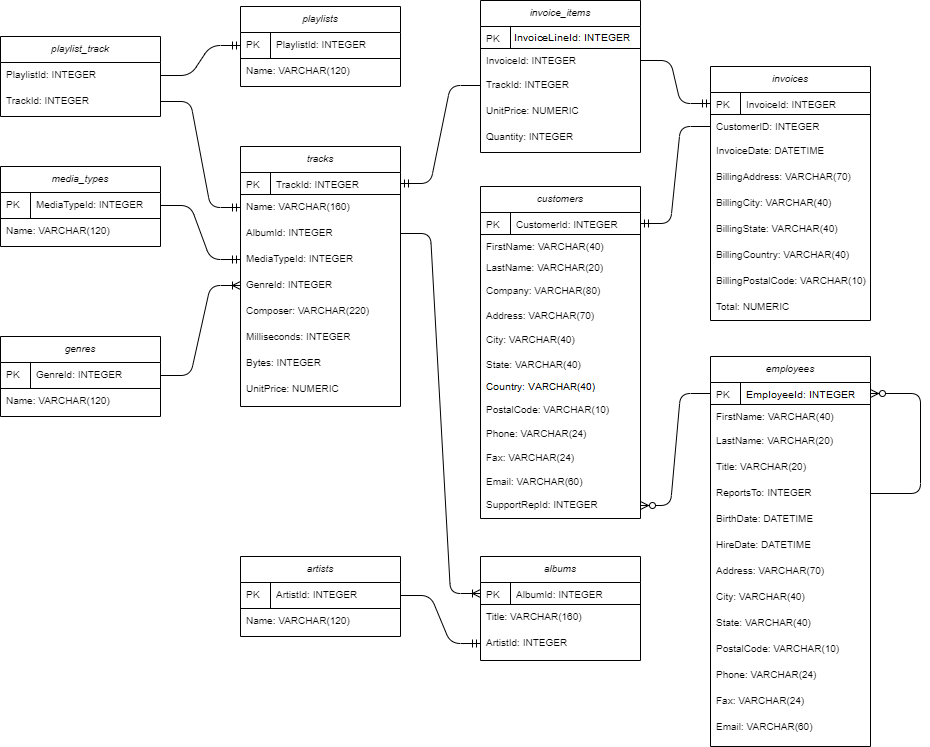
Apa arti simbol di garis penghubung antar tabel pada database schema?#
Simbol pada garis penghubung antara Primary Key (PK) dan Foreign Key (FK) disebut juga sebagai kardinalitas. Ada banyak notasi yang digunakan untuk menyimbolkan sebuah kardinalitas, misalnya Information Engineering Style, Chen Style, Bachman Style, Martin Style, dan lain-lain. Berikut adalah notasi Crows Foot yang digunakan pada ERD chinook.db:
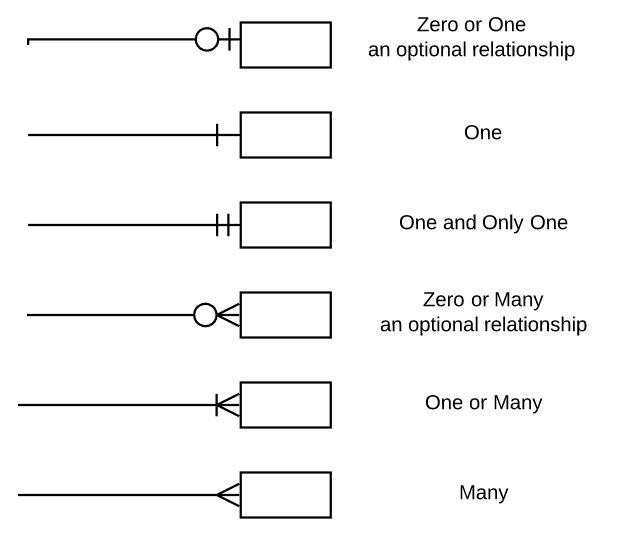
Berikut adalah cara membaca kardinalitas pada database chinook.db:
Satu
genresdapat memiliki satu atau lebihtracksSatu
trackshanya dapat memiliki satumedia_types,playlist_track, dan terdaftar pada tepat satuinvoice_itemsSatu
playlistshanya dapat terdaftar pada satuplaylist_trackSatu
albumsdapat memiliki satu atau lebihtracksSatu
albumshanya dapat terdaftar pada satuartistsSatu
invoice_itemshanya dapat terdaftar pada satuinvoicesSatu
invoiceshanya dapat dimiliki oleh satucustomerscustomersdanemployeesmemiliki hubungan yang opsional, karena bisa saja adaemployeesyang tidak berhubungan langsung dengancustomers(misalkan divisi IT)employeesmemiliki hubungan yang opsional dengan dirinya sendiri, karenaemployeesdengan jabatan paling tinggi (General Manager) tidak memerlukanReportsTo
Tidak ada aturan baku dalam membuat kardinalitas, karena disesuaikan berdasarkan kasusnya. Penentuan kardinalitas masuk ke dalam proses database design yang merupakan tanggung jawab seorang database architect, di luar dari scope seorang data analyst atau data scientist.
Apa perbedaan ERD dengan database dictionary?#
Perbedaan antara ERD (Entity-Relationship Diagram) dan database dictionary:
ERD adalah representasi grafis dari hubungan antara entitas dalam suatu database. Ini menunjukkan bagaimana entitas dalam database terkait satu sama lain.
Database dictionary adalah dokumen atau kumpulan informasi tertulis yang menjelaskan setiap elemen dalam database, termasuk tabel, kolom, tipe data, dan konstrain. Ini berfungsi sebagai referensi untuk pemahaman struktur dan isian database.
Bagaimana cara mengetahui list table dan kolom pada sqlite melalui query apabila database schema tidak diberikan?#
Informasi detail mengenai database dapat diperoleh melalui sqlite_master seperti di bawah ini:
conn = sqlite3.connect("data_input/chinook.db")
tables = pd.read_sql_query(
'''
SELECT name, sql
FROM sqlite_master
WHERE type = 'table' AND name NOT LIKE 'sqlite_%'
''',
conn,
index_col='name')
tables
| sql | |
|---|---|
| name | |
| albums | CREATE TABLE "albums"\r\n(\r\n [AlbumId] IN... |
| artists | CREATE TABLE "artists"\r\n(\r\n [ArtistId] ... |
| customers | CREATE TABLE "customers"\r\n(\r\n [Customer... |
| employees | CREATE TABLE "employees"\r\n(\r\n [Employee... |
| genres | CREATE TABLE "genres"\r\n(\r\n [GenreId] IN... |
| invoices | CREATE TABLE "invoices"\r\n(\r\n [InvoiceId... |
| invoice_items | CREATE TABLE "invoice_items"\r\n(\r\n [Invo... |
| media_types | CREATE TABLE "media_types"\r\n(\r\n [MediaT... |
| playlists | CREATE TABLE "playlists"\r\n(\r\n [Playlist... |
| playlist_track | CREATE TABLE "playlist_track"\r\n(\r\n [Pla... |
| tracks | CREATE TABLE "tracks"\r\n(\r\n [TrackId] IN... |
Untuk melihat detail kolom pada masing-masing tabel, silahkan akses DataFrame tables sesuai nama tabelnya. Contohnya kita ingin melihat struktur kolom dari tabel albums:
print(tables.loc['albums', 'sql'])
CREATE TABLE "albums"
(
[AlbumId] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
FOREIGN KEY ([ArtistId]) REFERENCES "artists" ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
SQL query tersebut disebut sebagai Data Definition Language (DDL). Berikut adalah informasi yang ditampilkan:
Nama kolom, contoh:
[AlbumId],[Title],[ArtistId]Tipe data, contoh:
INTEGER,NVARCHAR(160)Kolom unique sebagai key, contoh:
PRIMARY KEY,FOREIGN KEYPengaturan lainnya, contoh:
AUTOINCREMENT,NOT NULL
Apakah ada cara untuk auto-generate database schema dalam bentuk diagram?#
Ada beberapa software yang dapat kita gunakan untuk membuat diagram secara otomatis dari database yang dimiliki, diantaranya adalah:
Database and SQL Concepts#
Apa itu API dan DBAPI?#
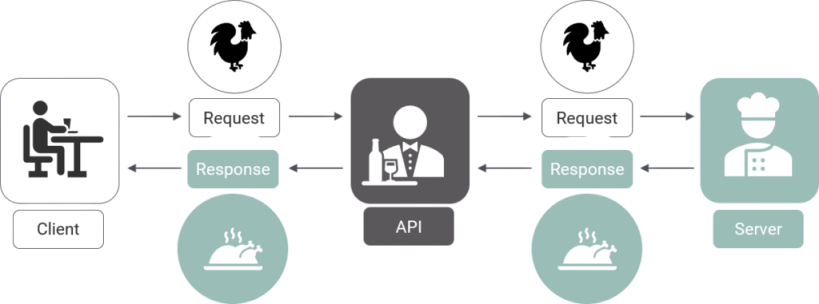
API (Application Programming Interface) adalah suatu aplikasi sebagai jembatan antara server dan client agar kita bisa melakukan fungsi tertentu tanpa mengetahui bagaimana proses dibalik fungsi tersebut. Salah satu contoh API yang telah kita gunakan di kelas adalah pandas-datareader untuk mengakses data saham dari Yahoo! Finance. Berikut adalah ilutrasi dari analogi API:
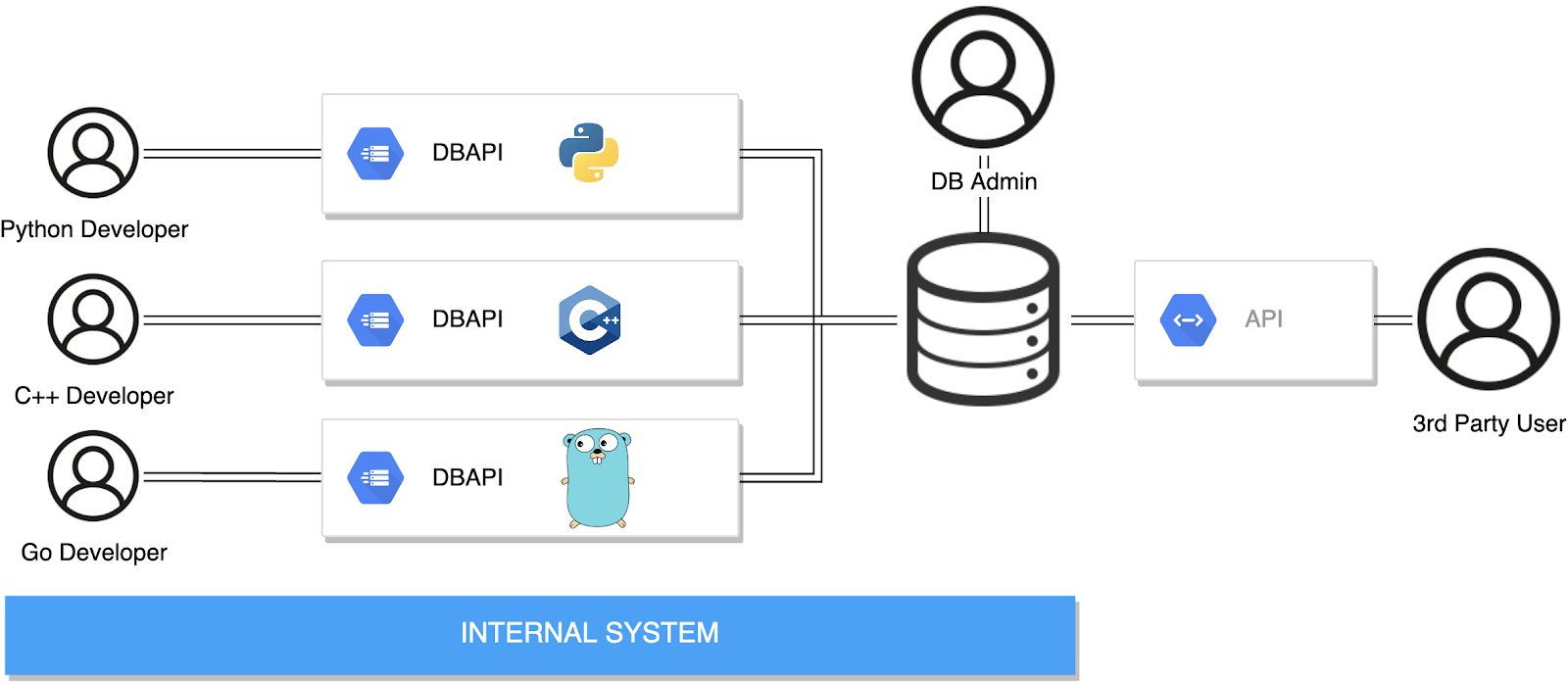
Sedangkan DBAPI adalah API yang spesifik digunakan untuk mengakses atau membangun koneksi dengan database (DB). Kalau di Python sendiri, wujud DBAPI yaitu berupa package. Contoh DBAPI untuk SQLite adalah sqlite3 sedangkan untuk MySQL adalah pymysql. Berikut ilustrasi DBAPI pada internal system dan API sebagai jembatan akses data untuk aplikasi pihak ketiga:
Apakah menggunakan SQL kita hanya dapat melakukan fetching data (SELECT) atau bisa mengubah datanya juga?#
Pada SQL terdapat banyak command yang dapat digunakan untuk berinteraksi dengan database yang dimiliki. Berdasarkan fungsinya, bahasa pada SQL query dapat dibagi menjadi empat:
Data Manipulation Language (DML): digunakan untuk mengoperasikan data pada tabel
Query:
INSERT,SELECT,UPDATE,DELETE
Data Definition Language (DDL): digunakan untuk mengoperasikan struktur tabel
Query:
CREATE,ALTER,RENAME,DROP
Data Control Language (DCL): digunakan untuk pengaturan akses database
Query:
GRANT,REVOKE
Transaction Processing Language (TCL): digunakan untuk versioning query
Query:
ROLLBACK,COMMIT
DML adalah query yang sering digunakan untuk Data Analyst maupun Data Scientist. Berikut adalah contohnya selain SELECT:
INSERT: menambahkan observasi baru pada tabel
Misalkan kita ingin menambahkan 3 artists baru, yaitu Artist1, Artist2, dan Artist3:
cursor = conn.cursor()
insert_data = [('Artist1', ),
('Artist2', ),
('Artist3', )]
cursor.executemany('INSERT INTO artists(Name) VALUES(?)', insert_data)
conn.commit()
pd.read_sql_query('SELECT * FROM artists', conn).tail()
| ArtistId | Name | |
|---|---|---|
| 273 | 274 | Nash Ensemble |
| 274 | 275 | Philip Glass Ensemble |
| 275 | 276 | Artist1 |
| 276 | 277 | Artist2 |
| 277 | 278 | Artist3 |
UPDATE: mengubah nilai suatu observasi pada tabel
Misalkan kita ingin mengubah Name dari artists berdasarkan ArtistId:
cursor = conn.cursor()
edit_data = [('UpdatedArtist1', 276),
('UpdatedArtist2', 277),
('UpdatedArtist3', 278)]
cursor.executemany('UPDATE artists SET Name = ? WHERE ArtistId = ?', edit_data)
conn.commit()
pd.read_sql_query('SELECT * FROM artists', conn).tail()
| ArtistId | Name | |
|---|---|---|
| 273 | 274 | Nash Ensemble |
| 274 | 275 | Philip Glass Ensemble |
| 275 | 276 | UpdatedArtist1 |
| 276 | 277 | UpdatedArtist2 |
| 277 | 278 | UpdatedArtist3 |
DELETE: menghapus observasi pada tabel
Misalkan kita ingin menghapus artists berdasarkan ArtistId:
cursor = conn.cursor()
delete_data = [(276,),
(277,),
(278,)]
cursor.executemany('DELETE FROM artists WHERE ArtistId = ?', delete_data)
conn.commit()
pd.read_sql_query('SELECT * FROM artists', conn).tail()
| ArtistId | Name | |
|---|---|---|
| 270 | 271 | Mela Tenenbaum, Pro Musica Prague & Richard Kapp |
| 271 | 272 | Emerson String Quartet |
| 272 | 273 | C. Monteverdi, Nigel Rogers - Chiaroscuro; Lon... |
| 273 | 274 | Nash Ensemble |
| 274 | 275 | Philip Glass Ensemble |
Code berikut digunakan untuk me-reset kembali AUTOINCREMENT dari kolom ArtistId agar mulai seperti semula.
cursor = conn.cursor()
cursor.execute('UPDATE SQLITE_SEQUENCE SET SEQ=275 WHERE NAME="artists"')
conn.commit()
SQL Query in Python#
Apakah itu sqlite3? Adakah konektor database selain sqlite3?#
SQLite adalah sistem basis data yang menggunakan file dalam penyimpanannya (contohnya chinook.db) sehingga tidak memerlukan sebuah server, semua terjadi di sisi client. sqlite3 adalah Database API (DBAPI) di Python untuk melakukan koneksi ke SQLite. Documentation sqlite3
Terdapat konektor database lainnya tergantung sistem manajemen database (DBMS) yang digunakan, berikut adalah diantaranya yang umum digunakan:
pymysqladalah DBAPI untuk MySQL, yaitu open-source relational DBMS yang sifatnya client-server dan umumnya digunakan untuk database sebuah website. Documentation pymysql```{python} import pymysql conn = pymysql.connect( host = HOST_NAME, port = PORT_NUMBER, user = USER_NAME, password = PASSWORD, db = DATABASE_NAME) ```cx_Oracleadalah DBAPI untuk Oracle Database, yaitu object-relational DBMS yang umumnya digunakan untuk online transaction processing dan data warehousing. Documentation cx_Oracle.```{python} import cx_Oracle # data source name from tnsnames.ora file dsn_tns = cx_Oracle.makedsn( HOST_NAME, PORT_NUMBER service_name = SERVICE_NAME) # connection conn = cx_Oracle.connect( user = USER_NAME, password = PASSWORD, dsn = dsn_tns) ```psycopg2adalah DBAPI untuk PostgreSQL, yaitu open-source object-relational DBMS. Documentation psycopg.```{python} import psycopg2 conn = psycopg2.connect( host = HOST_NAME, port = PORT_NUMBER, user = USER_NAME, password = PASSWORD, database = DATABASE_NAME) ```
Apakah ada alternatif menggunakan backslash \ untuk meminimalisir kesalahan pengetikan query?#
Terdapat resiko kesalahan pengetikan yang tinggi ketika menggunakan \ sehingga diperlukan ketelitian yang lebih pada contoh query berikut:
pd.read_sql_query("SELECT * \
FROM artists \
LIMIT 5", conn)
| ArtistId | Name | |
|---|---|---|
| 0 | 1 | AC/DC |
| 1 | 2 | Accept |
| 2 | 3 | Aerosmith |
| 3 | 4 | Alanis Morissette |
| 4 | 5 | Alice In Chains |
Alternatifnya adalah dengan menggunakan kutip sebanyak tiga kali ''' atau """ di antara query sehingga kita bebas melakukan enter tanpa menggunakan \.
pd.read_sql_query(
'''
SELECT *
FROM artists
LIMIT 5
''', conn)
| ArtistId | Name | |
|---|---|---|
| 0 | 1 | AC/DC |
| 1 | 2 | Accept |
| 2 | 3 | Aerosmith |
| 3 | 4 | Alanis Morissette |
| 4 | 5 | Alice In Chains |
Adakah ketentuan urutan pembacaan tabel saat melakukan operasi LEFT JOIN? Jika ya, sebaiknya tabel mana yang didahulukan?#
Pada operasi LEFT JOIN, urutan pembacaan tabel dapat mempengaruhi hasil query apabila antar tabel memiliki hubungan yang opsional. Urutan pembacaan tabel disesuaikan dengan kebutuhan. Posisikan sebuah tabel sebagai left table apabila kita ingin mempertahankan seluruh baris pada tabel tersebut, mengizinkan adanya missing value pada data.
Contohnya pada tabel employees dengan customers hubungannya opsional karena tidak semua employees melayani customers secara langsung, hanya divisi Sales saja.
Case 1: Apabila kita ingin menampilkan semua data employees terlepas dari ada atau tidaknya customers yang dilayani, maka letakkan employees sebagai left table:
case1 = pd.read_sql_query(
'''
SELECT *
FROM employees
LEFT JOIN customers
ON employees.EmployeeId = customers.SupportRepId
''', conn)
case1.head()
| EmployeeId | LastName | FirstName | Title | ReportsTo | BirthDate | HireDate | Address | City | State | ... | Company | Address | City | State | Country | PostalCode | Phone | Fax | SupportRepId | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Adams | Andrew | General Manager | NaN | 1962-02-18 00:00:00 | 2002-08-14 00:00:00 | 11120 Jasper Ave NW | Edmonton | AB | ... | None | None | None | None | None | None | None | None | None | NaN |
| 1 | 2 | Edwards | Nancy | Sales Manager | 1.0 | 1958-12-08 00:00:00 | 2002-05-01 00:00:00 | 825 8 Ave SW | Calgary | AB | ... | None | None | None | None | None | None | None | None | None | NaN |
| 2 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | ... | Embraer - Empresa Brasileira de Aeronáutica S.A. | Av. Brigadeiro Faria Lima, 2170 | São José dos Campos | SP | Brazil | 12227-000 | +55 (12) 3923-5555 | +55 (12) 3923-5566 | luisg@embraer.com.br | 3.0 |
| 3 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | ... | None | 1498 rue Bélanger | Montréal | QC | Canada | H2G 1A7 | +1 (514) 721-4711 | None | ftremblay@gmail.com | 3.0 |
| 4 | 3 | Peacock | Jane | Sales Support Agent | 2.0 | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | ... | Riotur | Praça Pio X, 119 | Rio de Janeiro | RJ | Brazil | 20040-020 | +55 (21) 2271-7000 | +55 (21) 2271-7070 | roberto.almeida@riotur.gov.br | 3.0 |
5 rows × 28 columns
Case 2: Sebaliknya, apabila kita hanya ingin menampilkan semua data customers yang pernah dilayani oleh seorang employees, maka letakkan customers sebagai left table:
case2 = pd.read_sql_query(
'''
SELECT *
FROM customers
LEFT JOIN employees
ON employees.EmployeeId = customers.SupportRepId
''', conn)
case2.head()
| CustomerId | FirstName | LastName | Company | Address | City | State | Country | PostalCode | Phone | ... | BirthDate | HireDate | Address | City | State | Country | PostalCode | Phone | Fax | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Luís | Gonçalves | Embraer - Empresa Brasileira de Aeronáutica S.A. | Av. Brigadeiro Faria Lima, 2170 | São José dos Campos | SP | Brazil | 12227-000 | +55 (12) 3923-5555 | ... | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com |
| 1 | 2 | Leonie | Köhler | None | Theodor-Heuss-Straße 34 | Stuttgart | None | Germany | 70174 | +49 0711 2842222 | ... | 1965-03-03 00:00:00 | 2003-10-17 00:00:00 | 7727B 41 Ave | Calgary | AB | Canada | T3B 1Y7 | 1 (780) 836-9987 | 1 (780) 836-9543 | steve@chinookcorp.com |
| 2 | 3 | François | Tremblay | None | 1498 rue Bélanger | Montréal | QC | Canada | H2G 1A7 | +1 (514) 721-4711 | ... | 1973-08-29 00:00:00 | 2002-04-01 00:00:00 | 1111 6 Ave SW | Calgary | AB | Canada | T2P 5M5 | +1 (403) 262-3443 | +1 (403) 262-6712 | jane@chinookcorp.com |
| 3 | 4 | Bjørn | Hansen | None | Ullevålsveien 14 | Oslo | None | Norway | 0171 | +47 22 44 22 22 | ... | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com |
| 4 | 5 | František | Wichterlová | JetBrains s.r.o. | Klanova 9/506 | Prague | None | Czech Republic | 14700 | +420 2 4172 5555 | ... | 1947-09-19 00:00:00 | 2003-05-03 00:00:00 | 683 10 Street SW | Calgary | AB | Canada | T2P 5G3 | +1 (403) 263-4423 | +1 (403) 263-4289 | margaret@chinookcorp.com |
5 rows × 28 columns
Apabila diperhatikan, kedua tabel memiliki jumlah baris yang berbeda yaitu 5, menandakan ada 5 employees yang tidak pernah melayani customers sama sekali.
print(f"employees LEFT JOIN customers: {case1.shape}")
print(f"customers LEFT JOIN employees: {case2.shape}")
employees LEFT JOIN customers: (64, 28)
customers LEFT JOIN employees: (59, 28)
Adakah operasi JOIN tabel pada pandas? Jika ada, apa perbedaannya dengan di SQL?#
Misal kita ingin mereplikasi hasil query tabel berikut:
pd.read_sql_query(
'''
SELECT albums.*, Name
FROM albums
LEFT JOIN artists
ON albums.ArtistId = artists.ArtistId
''', conn)
| AlbumId | Title | ArtistId | Name | |
|---|---|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You | 1 | AC/DC |
| 1 | 2 | Balls to the Wall | 2 | Accept |
| 2 | 3 | Restless and Wild | 2 | Accept |
| 3 | 4 | Let There Be Rock | 1 | AC/DC |
| 4 | 5 | Big Ones | 3 | Aerosmith |
| ... | ... | ... | ... | ... |
| 342 | 343 | Respighi:Pines of Rome | 226 | Eugene Ormandy |
| 343 | 344 | Schubert: The Late String Quartets & String Qu... | 272 | Emerson String Quartet |
| 344 | 345 | Monteverdi: L'Orfeo | 273 | C. Monteverdi, Nigel Rogers - Chiaroscuro; Lon... |
| 345 | 346 | Mozart: Chamber Music | 274 | Nash Ensemble |
| 346 | 347 | Koyaanisqatsi (Soundtrack from the Motion Pict... | 275 | Philip Glass Ensemble |
347 rows × 4 columns
Misalkan kita memiliki dua tabel yang terpisah, yaitu albums dan artists. Dengan menggunakan method .join() kita dapat melakukan operasi yang sama persis dengan SQL JOIN.
albums = pd.read_sql_query("SELECT * FROM albums", conn)
artists = pd.read_sql_query("SELECT * FROM artists", conn)
albums.join(artists.set_index('ArtistId'), on='ArtistId', how='left')
| AlbumId | Title | ArtistId | Name | |
|---|---|---|---|---|
| 0 | 1 | For Those About To Rock We Salute You | 1 | AC/DC |
| 1 | 2 | Balls to the Wall | 2 | Accept |
| 2 | 3 | Restless and Wild | 2 | Accept |
| 3 | 4 | Let There Be Rock | 1 | AC/DC |
| 4 | 5 | Big Ones | 3 | Aerosmith |
| ... | ... | ... | ... | ... |
| 342 | 343 | Respighi:Pines of Rome | 226 | Eugene Ormandy |
| 343 | 344 | Schubert: The Late String Quartets & String Qu... | 272 | Emerson String Quartet |
| 344 | 345 | Monteverdi: L'Orfeo | 273 | C. Monteverdi, Nigel Rogers - Chiaroscuro; Lon... |
| 345 | 346 | Mozart: Chamber Music | 274 | Nash Ensemble |
| 346 | 347 | Koyaanisqatsi (Soundtrack from the Motion Pict... | 275 | Philip Glass Ensemble |
347 rows × 4 columns
Walaupun hasilnya sama, terdapat perbedaan penggunaan SQL JOIN dan pandas method .join():
Operasi JOIN pada SQL dilakukan di sisi server kemudian dikembalikan hasil gabungannya
Method
.join()pandasdilakukan di sisi client dan masing-masing tabel masih tersimpan pada memory
Sehingga, apabila kita memiliki data dengan volume yang besar (misal milyaran baris), maka penggunaan operasi JOIN dengan SQL akan jauh lebih cepat dibandingkan .join() pada pandas.
Silahkan simak kembali materi Under dan Over fetching pada course SQL.
Apakah ada ketentuan urutan WHERE, GROUP BY, ORDER BY, dan LIMIT?#
Ketentuan urutan WHERE, GROUP BY, ORDER BY, dan LIMIT dalam SQL biasanya diikuti dalam urutan berikut:
WHERE: Digunakan untuk melakukan pemfilteran data berdasarkan kriteria tertentu.GROUP BY: Digunakan untuk mengelompokkan baris data yang memiliki nilai yang sama dalam kolom tertentu.ORDER BY: Digunakan untuk mengurutkan hasil query berdasarkan kolom tertentu.LIMIT: Digunakan untuk membatasi jumlah baris hasil query yang akan ditampilkan.
Tetapi, tidak selalu harus mengikuti urutan ini secara ketat, tergantung pada kebutuhan query.
Bagaimana cara konversi data SQLite menjadi flat files (misalnya Excel)?#
Kasus: kita ingin mengubah data chinook.db menjadi file Excel. Dalam kasus ini masih memungkinkan dikarenakan ukuran database cukup kecil. Apabila volume data sudah sangat besar, tidak sarankan menggunakan flat files. Berikut adalah langkahnya:
Pertama, kita peroleh daftar nama tabel yang tersimpan pada database chinook.db melalui sqlite_master
table_list = pd.read_sql_query(
'''
SELECT name
FROM sqlite_master
WHERE type = 'table' AND name NOT LIKE 'sqlite_%'
''', conn)['name'].values
table_list
array(['albums', 'artists', 'customers', 'employees', 'genres',
'invoices', 'invoice_items', 'media_types', 'playlists',
'playlist_track', 'tracks'], dtype=object)
Kemudian secara iteratif pandas membaca tabel dan menyimpannya ke file Excel dengan nama sheet yang berbeda.
writer = pd.ExcelWriter('data_input/chinook.xlsx', engine='xlsxwriter')
for table in table_list:
query = f"SELECT * FROM {table}"
df = pd.read_sql_query(query, conn)
df.to_excel(writer, sheet_name=table, index=False)
writer.save()
Berikut adalah contoh output chinook.xlsx yang dihasilkan dari code di atas:

Sebaliknya, bagaimana cara konversi data flat files menjadi SQLite?#
Kasus: kita ingin mengubah kembali data chinook.xlsx menjadi chinook_new.db dimana 1 sheet Excel akan menjadi 1 tabel pada SQLite. Berikut adalah langkahnya:
Siapkan object
connectiondancursoruntuk database yang baru, yaituchinook_new.db.
conn_new = sqlite3.connect("data_input/chinook_new.db")
cursor = conn_new.cursor()
Siapkan juga Data Definition Language berupa perintah
CREATE TABLEyang mendefinisikan masing-masing tabel berisi kolom beserta tipe datanya, dan hubungan antar tabel. Tahap ini merupakan ranah seorang database architect, anggap sudah disediakan melaluichinook_DDL.txt.
f = open("data_input/chinook_DDL.txt", 'r')
ddl_query_list = f.read().split(';')
f.close()
print(ddl_query_list[0]) # contoh DDL untuk tabel albums
CREATE TABLE IF NOT EXISTS "albums"
(
[AlbumId] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
[Title] NVARCHAR(160) NOT NULL,
[ArtistId] INTEGER NOT NULL,
FOREIGN KEY ([ArtistId]) REFERENCES "artists" ([ArtistId])
ON DELETE NO ACTION ON UPDATE NO ACTION
)
Query yang tersimpan pada
ddl_query_listdieksekusi satu per satu dengancursoragar terbentuk struktur tabel yang sesuai.
for query in ddl_query_list:
cursor.execute(query)
Melalui informasi database yang tersimpan pada sqlite_master, kita dapat memastikan bahwa semua tabel sudah terbentuk dengan baik. Sampai pada tahap ini, tabel pada chinook_new.db masih kosong, belum ada datanya.
pd.read_sql_query("SELECT * FROM sqlite_master", conn_new)
| type | name | tbl_name | rootpage | sql | |
|---|---|---|---|---|---|
| 0 | table | albums | albums | 2 | CREATE TABLE "albums"\n(\n [AlbumId] INTEGE... |
| 1 | table | sqlite_sequence | sqlite_sequence | 3 | CREATE TABLE sqlite_sequence(name,seq) |
| 2 | table | artists | artists | 4 | CREATE TABLE "artists"\n(\n [ArtistId] INTE... |
| 3 | table | customers | customers | 5 | CREATE TABLE "customers"\n(\n [CustomerId] ... |
| 4 | table | employees | employees | 6 | CREATE TABLE "employees"\n(\n [EmployeeId] ... |
| 5 | table | genres | genres | 7 | CREATE TABLE "genres"\n(\n [GenreId] INTEGE... |
| 6 | table | invoices | invoices | 8 | CREATE TABLE "invoices"\n(\n [InvoiceId] IN... |
| 7 | table | invoice_items | invoice_items | 9 | CREATE TABLE "invoice_items"\n(\n [InvoiceL... |
| 8 | table | media_types | media_types | 10 | CREATE TABLE "media_types"\n(\n [MediaTypeI... |
| 9 | table | playlists | playlists | 11 | CREATE TABLE "playlists"\n(\n [PlaylistId] ... |
| 10 | table | playlist_track | playlist_track | 12 | CREATE TABLE "playlist_track"\n(\n [Playlis... |
| 11 | index | sqlite_autoindex_playlist_track_1 | playlist_track | 13 | None |
| 12 | table | tracks | tracks | 14 | CREATE TABLE "tracks"\n(\n [TrackId] INTEGE... |
# belum ada data
pd.read_sql_query("SELECT * FROM artists", conn_new)
| ArtistId | Name |
|---|
Pada tahap akhir, kita “populate” database
chinook_new.dbdari datachinook.xlsxdengan menggunakan method.to_sql(). Pastikan kedua hal berikut:Nama sheet pada Excel harus sesuai dengan nama tabel pada SQLite
Nama kolom pada setiap sheet Excel harus sesuai dengan perintah DDL yang telah didefinisikan
sheet_df_dict = pd.read_excel('data_input/chinook.xlsx', sheet_name=None)
for sheet_name, df in sheet_df_dict.items():
df.to_sql(sheet_name, conn_new, if_exists='replace', index=False)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-27-2b6d35904cbb> in <module>
----> 1 sheet_df_dict = pd.read_excel('data_input/chinook.xlsx', sheet_name=None)
2
3 for sheet_name, df in sheet_df_dict.items():
4 df.to_sql(sheet_name, conn_new, if_exists='replace', index=False)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/pandas/util/_decorators.py in wrapper(*args, **kwargs)
309 stacklevel=stacklevel,
310 )
--> 311 return func(*args, **kwargs)
312
313 return wrapper
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/pandas/io/excel/_base.py in read_excel(io, sheet_name, header, names, index_col, usecols, squeeze, dtype, engine, converters, true_values, false_values, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, parse_dates, date_parser, thousands, comment, skipfooter, convert_float, mangle_dupe_cols, storage_options)
362 if not isinstance(io, ExcelFile):
363 should_close = True
--> 364 io = ExcelFile(io, storage_options=storage_options, engine=engine)
365 elif engine and engine != io.engine:
366 raise ValueError(
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/pandas/io/excel/_base.py in __init__(self, path_or_buffer, engine, storage_options)
1231 self.storage_options = storage_options
1232
-> 1233 self._reader = self._engines[engine](self._io, storage_options=storage_options)
1234
1235 def __fspath__(self):
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/pandas/io/excel/_openpyxl.py in __init__(self, filepath_or_buffer, storage_options)
519 passed to fsspec for appropriate URLs (see ``_get_filepath_or_buffer``)
520 """
--> 521 import_optional_dependency("openpyxl")
522 super().__init__(filepath_or_buffer, storage_options=storage_options)
523
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/pandas/compat/_optional.py in import_optional_dependency(name, extra, errors, min_version)
113 )
114 try:
--> 115 module = importlib.import_module(name)
116 except ImportError:
117 if errors == "raise":
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/__init__.py in import_module(name, package)
125 break
126 level += 1
--> 127 return _bootstrap._gcd_import(name[level:], package, level)
128
129
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap.py in _gcd_import(name, package, level)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap.py in _find_and_load(name, import_)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap.py in _find_and_load_unlocked(name, import_)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap.py in _load_unlocked(spec)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap_external.py in exec_module(self, module)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/importlib/_bootstrap.py in _call_with_frames_removed(f, *args, **kwds)
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/openpyxl/__init__.py in <module>
2
3
----> 4 from openpyxl.compat.numbers import NUMPY, PANDAS
5 from openpyxl.xml import DEFUSEDXML, LXML
6 from openpyxl.workbook import Workbook
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/openpyxl/compat/__init__.py in <module>
1 # Copyright (c) 2010-2020 openpyxl
2
----> 3 from .numbers import NUMERIC_TYPES
4 from .strings import safe_string
5
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/openpyxl/compat/numbers.py in <module>
39 numpy.float32,
40 numpy.float64,
---> 41 numpy.float,
42 numpy.bool_,
43 numpy.floating,
~/.local/share/mise/installs/python/3.8.20/lib/python3.8/site-packages/numpy/__init__.py in __getattr__(attr)
303
304 if attr in __former_attrs__:
--> 305 raise AttributeError(__former_attrs__[attr])
306
307 # Importing Tester requires importing all of UnitTest which is not a
AttributeError: module 'numpy' has no attribute 'float'.
`np.float` was a deprecated alias for the builtin `float`. To avoid this error in existing code, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
Kita pastikan bahwa data sudah dimasukkan ke dalam tabel dengan baik:
pd.read_sql_query("SELECT * FROM artists", conn_new)
| ArtistId | Name | |
|---|---|---|
| 0 | 1 | AC/DC |
| 1 | 2 | Accept |
| 2 | 3 | Aerosmith |
| 3 | 4 | Alanis Morissette |
| 4 | 5 | Alice In Chains |
| ... | ... | ... |
| 270 | 271 | Mela Tenenbaum, Pro Musica Prague & Richard Kapp |
| 271 | 272 | Emerson String Quartet |
| 272 | 273 | C. Monteverdi, Nigel Rogers - Chiaroscuro; Lon... |
| 273 | 274 | Nash Ensemble |
| 274 | 275 | Philip Glass Ensemble |
275 rows × 2 columns
# menutup semua koneksi database
conn.close()
conn_new.close()
Bagaimana cara melakukan join antara dua sumber data jika salah satunya berasal dari database dan yang lainnya berasal dari flatfiles?#
Jika ada 2 sumber data, satu dari database dan satu lagi dari flat file, cara untuk melakukan join antara keduanya dapat dilakukan dengan menggunakan teknik ETL (Extract, Transform, Load).
Tentu, berikut adalah langkah-langkahnya:
Ekstraksi (Extract):
Ambil data dari sumber flat file. Ini dapat dilakukan dengan membaca file menggunakan modul yang sesuai, seperti
pandasuntuk CSV, Excel, atau teks, atau menggunakan modul lain tergantung pada format file yang digunakan.Ambil data dari database menggunakan koneksi database yang sesuai, seperti
sqlite3untuk SQLite,psycopg2untuk PostgreSQL, atau modul lainnya yang sesuai dengan jenis database yang Anda gunakan.
Transformasi (Transform):
Jika diperlukan, lakukan transformasi data. Ini mungkin melibatkan pemrosesan data, membersihkan data yang tidak valid, mengubah format kolom, atau melakukan operasi transformasi lainnya agar data cocok dengan format yang diinginkan atau untuk memenuhi kebutuhan analisis.
Pemuatan (Load):
Simpan data hasil ekstraksi dan transformasi ke dalam database. Anda bisa menggunakan perintah SQL untuk memasukkan data ke dalam tabel yang sesuai di database Anda.
Join:
Setelah kedua sumber data berada dalam satu database, Anda dapat melakukan join menggunakan perintah SQL biasa. Anda bisa menggunakan perintah
JOINdalam SQL untuk menggabungkan data dari kedua tabel berdasarkan kriteria yang diinginkan, seperti kunci primer atau kolom tertentu.
Berikut adalah contoh langkah-langkah dalam kode Python menggunakan pandas dan sqlite3 untuk melakukan ETL dan join antara data dari database dan flat file:
import pandas as pd
import sqlite3
# Ekstraksi (Extract)
data_flatfile = pd.read_csv('data_flatfile.csv')
conn = sqlite3.connect('database.db')
query_db = "SELECT * FROM tabel_database"
data_db = pd.read_sql_query(query_db, conn)
# Transformasi (Transform) - Opsional, tergantung kebutuhan
# Pemuatan (Load)
# Menyimpan data dari flat file ke dalam database (misalnya, ke dalam tabel 'flatfile_data')
data_flatfile.to_sql('flatfile_data', conn, if_exists='replace', index=False)
# Join
query_join = """
SELECT *
FROM tabel_database db
JOIN flatfile_data ff ON db.id = ff.id
"""
data_join = pd.read_sql_query(query_join, conn)
# Menampilkan hasil join
print(data_join)
Pastikan Anda menyesuaikan nama file, nama tabel, dan kolom kunci saat melakukan ekstraksi, transformasi, dan join sesuai dengan kebutuhan Anda.
Apakah ada cara untuk mengambil data dari database secara otomatis atau menggunakan scheduler jika ada tambahan data dari database?#
Tiga cara yang sering digunakan untuk mengambil data dari database secara otomatis atau menggunakan scheduler adalah:
Internal Database Scheduler: Sistem database seperti Oracle Database, MySQL, dan SQL Server menyediakan fitur internal untuk menjadwalkan eksekusi query atau tugas tertentu. Anda dapat menggunakan fitur ini untuk membuat jadwal pengambilan data secara teratur langsung dari database.
Cron Jobs: Pada sistem operasi Unix atau Linux, pengguna dapat menggunakan cron jobs untuk menjadwalkan eksekusi skrip Python atau perintah SQL untuk mengambil data dari database pada interval waktu tertentu. Ini merupakan cara yang sangat umum dan efektif untuk mengatur jadwal pengambilan data. Contoh:
# menjadwalkan eksekusi skrip Python setiap hari pada pukul 3 pagi
0 3 * * * python /path/to/your/script.py
Apache Airflow: Apache Airflow adalah platform manajemen alur kerja yang kuat yang dapat digunakan untuk mengatur dan menjadwalkan proses ekstraksi data dari database dengan cara yang lebih canggih. Anda dapat membuat alur kerja (DAG) yang menentukan bagaimana data diambil, diubah, dan dimuat (ETL) pada jadwal tertentu.
Pilihan antara ketiga metode ini tergantung pada kebutuhan, preferensi, dan lingkungan teknologi yang digunakan oleh organisasi atau pengembang data. Sejauh ini, untuk kemudahan dan praktisi, kita dapat menggunakan Airflow. Jika ingin mempelajari lebih lanjut terkait scheduling menggunakan Airflow dapat melihat referensi berikut.