General Question#
Python Installation#
(Windows) Instalasi requirements.txt pada Anaconda Prompt#
Berikut adalah langkah-langkah untuk menginstal paket-paket yang tercantum dalam file requirements.txt ke dalam environment Anaconda tertentu menggunakan Anaconda Prompt di Windows:
Buka Anaconda Prompt:
Tekan
Win+S, ketik “Anaconda Prompt,” dan tekanEnteruntuk membukanya.
Aktifkan environment yang Dituju:
Untuk mengaktifkan environment di mana Anda ingin menginstal paket-paket tersebut, gunakan perintah berikut:
conda activate your_env_name
Ganti
your_env_namedengan nama environment Anda. Berikut contoh tampilan Anaconda Prompt: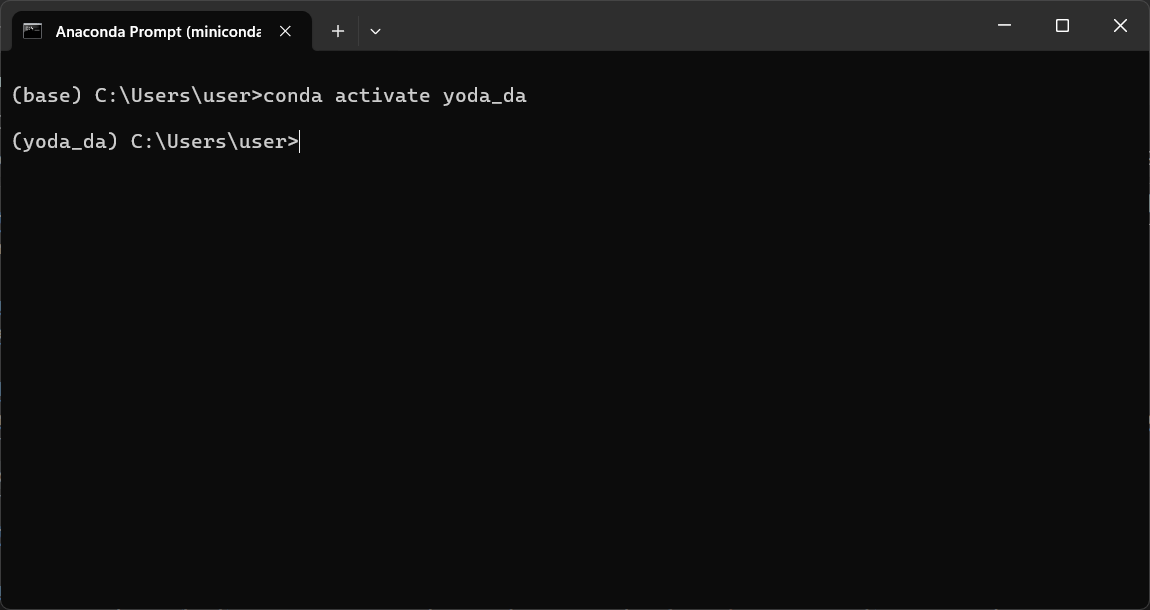
Arahkan ke Direktori yang Berisi
requirements.txt:Gunakan perintah
cduntuk masuk ke direktori tempat filerequirements.txtberada. Misalnya:cd path\to\your\directory
Ganti
path\to\your\directorydengan jalur direktori Anda yang sebenarnya.Instalasi Paket-Paket:
Gunakan
pipuntuk menginstal libraries yang tercantum dalamrequirements.txt. Jalankan perintah berikut:pip install -r requirements.txt
Jika Anda belum membuat environment tersebut, Anda bisa membuatnya dengan perintah:
conda create --name nama_environment_anda python=3.x
Ganti 3.x dengan versi Python yang Anda butuhkan.
Jika Anda mengalami masalah atau memerlukan kustomisasi lebih lanjut, jangan ragu untuk bertanya!
Installasi kernel di Visual Studio Code#
Setelah pembuatan environtment baru dan persiapan package, terdapat satu hal yang wajib untuk dimiliki sebuah environtment baru agar environtment tersebut dapat digunakan untuk menjalankan code Python, yaitu kernel.
Untuk keperluan installasi kernel sendiri di Visual Studi Code cukup mudah. Walaupun sebenarnya bisa melalui pip install ipykernel, biasanya secara otomatis akan diminta Visual Studio Code untuk install saat pertama kali menjalankan cell code pada environtment baru seperti gambar di bawah.
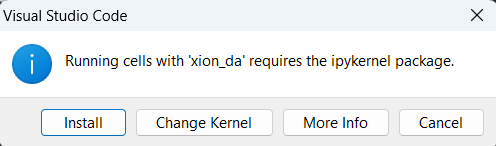
Bagaimana cara membuka Terminal pada Visual Studio Code?#
Untuk membuka Terminal pada Visual Studio Code, Anda dapat mengikuti langkah-langkah berikut:
Buka Visual Studio Code: Pastikan Anda telah menginstal Visual Studio Code di sistem Anda dan membukanya.
Pilih Proyek: Buka folder atau proyek yang ingin Anda kerjakan menggunakan Visual Studio Code.
Buka Terminal:
Gunakan pintasan keyboard dengan menekan:
Ctrl + Shift + `
Alternatifnya, Anda dapat mengklik menu Terminal yang terletak di bagian atas kiri panel > New Terminal.
Dengan melakukan salah satu cara di atas, Anda akan membuka Terminal di bagian bawah layar Visual Studio Code. Pastikan, khususnya bagi pengguna Windows, terminal yang terbuka adalah yang tertuliskan cmd atau Command Prompt
Khusus Pengguna Windows#
Pastikan Terminal yang terbuka adalah Command Prompt (cmd). Jika bukan, yaitu masih Powershell maka lakukan beberapa langkah berikut:
Klik
Ctrl + Shift + PCari “Select Default Profile”
Pilih “Command Prompt”
Lalu lakukan kembali cara membuat “New Terminal” (Ctrl + Shift + `)
Pastikan Terminal terhubung dengan Miniconda:
Ketik
conda activatedi terminal.Tekan Enter.
Periksa apakah muncul
(base)di sebelah path yang tampil di terminal. Jika muncul artinya Terminal telah terhubung dengan Miniconda.
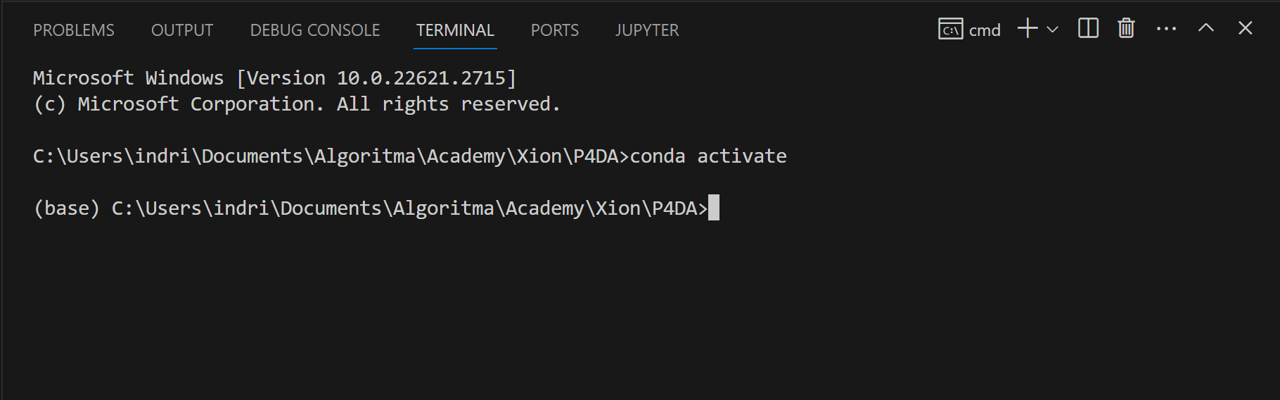
(Windows) Bagaimana Mengatasi Terminal yang tidak terhubung dengan Miniconda?#
Dalam hal ini artinya muncul
'conda' is not recognized as an internal or external commandsaat diketikkanconda activatepada Terminal.
Tentu, berikut langkah-langkahnya menggunakan fungsi pencarian di Windows:
Buka Anaconda Prompt
Cari dimana letak instalasi Conda dengan mengetikkan
where condapada Anaconda Prompt Salin path yang terlihat seperti ini:C:\Users\<username>\miniconda3\Library\bin⚠️ Catatan:
<username>adalah user name Anda sendiri.Cari “Environment Variables” melalui Windows Search:
Klik ikon Windows di sudut kiri bawah atau tekan tombol Windows pada keyboard.
Ketik
"Edit environment variables for your account"di kotak pencarian.
Tertampil jendela “Environment Variables”
Edit “Path” di Bagian “User variables” atau “System variables”:
Dalam jendela Environment Variables, temukan dan pilih variabel “Path” dalam bagian “User variables” (untuk pengguna saat ini)
Klik tombol “Edit…”
Tambahkan Path Baru:
Klik tombol “New”.
Ketik atau tempelkan path yang tadi diperoleh
C:\Users\<username>\miniconda3\Library\bin.⚠️ Catatan: <username> adalah user name Anda sendiri.
Klik “OK” untuk menutup setiap jendela yang telah terbuka.
Verifikasi Penambahan Path:
Tutup Visual Studio Code yang sebelumnya terbuka dan buka kembali Visual Studio Code-nya
Buka terminal baru atau restart terminal yang sudah terbuka sebelumnya.
Ketik
conda activatedan tekan Enter.Pastikan tidak ada lagi pesan kesalahan terkait
'conda' is not recognized as an internal or external command.
(Windows) Bagaimana jika New Terminal yang terbuka bukan Command Prompt (cmd), melainkan PowerShell?#
Jika Terminal baru yang terbuka di Visual Studio Code adalah PowerShell dan Anda ingin menggantinya menjadi Command Prompt (cmd) di sistem operasi Windows, Anda dapat mengikuti langkah-langkah berikut:
Buka Terminal: Buka Visual Studio Code dan pastikan Anda sudah membuka proyek atau folder.
Buka Pilihan Terminal: Pada bagian kanan atas terminal, Anda akan melihat dropdown (biasanya bertuliskan “Select Default Profile”). Klik pada dropdown tersebut.
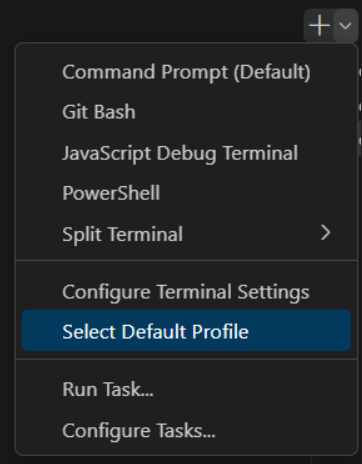
Alternatifnya,
Tekan Ctrl + Shift + P untuk membuka Command Palette. Lalu, ketik “Select Default Terminal” di Command Palette.
Pilih “Command Prompt” atau “Command Prompt (cmd)” dari opsi yang tersedia.
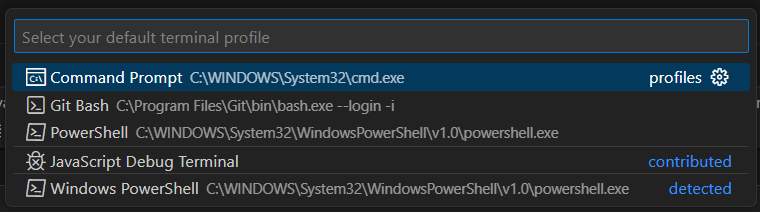
Buka Terminal ulang.
Jupyter Notebook#
Bagaimana cara membuat Table of Content pada Jupyter Notebook?#
Untuk menampilkan table of content (TOC), pastikan di dalam Jupyter Notebook sudah terinstall nbextensions. Jika sudah terinstall buka config nbextensions kemudian check pilihan Table of Content.
Apabila belum terinstall nbextensions, maka ikuti langkah pada poin di bawah ini untuk menginstall nbextensions.
Langkah menginstall nbextensions#
Install nbextensions
conda install -c conda-forge jupyter_contrib_nbextensions
Install configurator
conda install -c conda-forge jupyter_nbextensions_configurator
Mengaktifkan nbextensions pada Jupyter Notebook
jupyter nbextensions_configurator enable --user
Referensi: Dokumentasi nbextensions
Source Dataset#
Apakah terdapat link open source yang menyediakan data untuk latihan mandiri?#
Berikut referensi data yang dapat Anda gunakan:
Read & Transform Dataset#
Bagaimana cara mengubah format scientific menjadi format float pada data numerik?#
Format scientific dapat diubah menggunakan set_option() pada pandas. Berikut adalah syntax lengkapnya :
import pandas as pd
pd.set_option('display.float_format', lambda x: '%.3f' % x)
Anda dapat mengaplikasikan penggunaan nilai desimal setelah deklarasi fungsi lambda x: <nilai desimal>. Pada contoh di atas, kita mengapilkasikan 3 satuan angka desimal setelah tanda pemisah titik pada nilai float.
Syntax apakah yang digunakan untuk mengubah format dari int64 sehingga tampilan 1000000 berubah menjadi 1,000,000 ?#
Untuk mengubah tampilan output dengan pemisah koma pada angka, dapat menggunakan attribut display.float_format pada pandas. Berikut adalah syntax lengkapnya :
pd.options.display.float_format = '{:,}'.format
Bagaimana cara untuk mengganti nama kolom?#
Mengubah nama kolom dapat menggunakan method rename sebagai berikut :
df.rename(columns={"to_replace": "new_replace"})
Bagaimana cara untuk menambah baris (row) pada data?#
Salah satu cara yang bisa digunakan untuk menambahkan row adalah dengan menggunakan method concat(). Pada dasarnya kita harus membuat terlebih dahulu row yang akan ditambahkan dalam bentuk dataframe, kemudian gabungkan data baru dengan dataframe yang telah ada dengan method concat() by row.
df = pd.DataFrame({
'col1': [1, 2],
'col2': [3, 4]
})
df
| col1 | col2 | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 4 |
df2 = pd.DataFrame({
'col1': [5, 6],
'col2': [7, 8]
})
df2
| col1 | col2 | |
|---|---|---|
| 0 | 5 | 7 |
| 1 | 6 | 8 |
Menambahkan baris pada df2 ke df1 :
df = pd.concat(
[df, df2],
axis=0, # mengacu ke axis baris
ignore_index=True)
df
| col1 | col2 | |
|---|---|---|
| 0 | 1 | 3 |
| 1 | 2 | 4 |
| 2 | 5 | 7 |
| 3 | 6 | 8 |
Bagaimana cara menghapus kolom secara permanen?#
Menghapus kolom secara permanen dapat menggunakan syntax drop
df.drop(columns=['col2'], inplace=True)
df
| col1 | |
|---|---|
| 0 | 1 |
| 1 | 2 |
| 2 | 5 |
| 3 | 6 |
Bagaimana cara memisahkan satu file CSV menjadi beberapa file CSV?#
Kasus: Dataset kiva berisi transaksi pinjaman dari awal tahun 2014 sampai akhir tahun 2015. Kita ingin memisahkan data tersebut berdasarkan periode (tahun-bulan) dari posted_time pinjaman.
Maka dari itu, kita ekstrak terlebih dahulu informasi year_month yang dibutuhkan.
import pandas as pd
kiva = pd.read_csv("data_input/kiva.csv")
# meletakkan kolom year_month pada index 0
kiva.insert(
loc=0,
column='year_month',
value=kiva['posted_time'].astype('datetime64[ns]').dt.to_period('M'))
kiva.head()
| year_month | id | funded_amount | loan_amount | activity | sector | country | region | currency | partner_id | posted_time | funded_time | term_in_months | lender_count | repayment_interval | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2014-01 | 653051 | 300.0 | 300.0 | Fruits & Vegetables | Food | Pakistan | Lahore | PKR | 247 | 2014-01-01 06:12:39 | 2014-01-02 10:06:32 | 12 | 12 | irregular |
| 1 | 2014-01 | 653053 | 575.0 | 575.0 | Rickshaw | Transportation | Pakistan | Lahore | PKR | 247 | 2014-01-01 06:51:08 | 2014-01-02 09:17:23 | 11 | 14 | irregular |
| 2 | 2014-01 | 653068 | 150.0 | 150.0 | Transportation | Transportation | India | Maynaguri | INR | 334 | 2014-01-01 09:58:07 | 2014-01-01 16:01:36 | 43 | 6 | bullet |
| 3 | 2014-01 | 653063 | 200.0 | 200.0 | Embroidery | Arts | Pakistan | Lahore | PKR | 247 | 2014-01-01 08:03:11 | 2014-01-01 13:00:00 | 11 | 8 | irregular |
| 4 | 2014-01 | 653084 | 400.0 | 400.0 | Milk Sales | Food | Pakistan | Abdul Hakeem | PKR | 245 | 2014-01-01 11:53:19 | 2014-01-01 19:18:51 | 14 | 16 | monthly |
Kemudian kita sediakan satu folder tempat menampung pecahan file CSV ke dalam FOLDERPATH:
import os
FOLDERPATH = "data_input/kiva/"
if not os.path.exists(FOLDERPATH):
os.makedirs(FOLDERPATH)
Secara iteratif, lakukan conditional subsetting untuk DataFrame kiva berdasarkan masing-masing year_month. Hasil subset tersebut disimpan menggunakan method .to_csv() tanpa menggunakan nomor index.
for period in kiva['year_month'].unique():
kiva_subset = kiva[kiva['year_month'] == period]
filename = f"kiva-{period}.csv"
kiva_subset.to_csv(FOLDERPATH + filename, index=False)
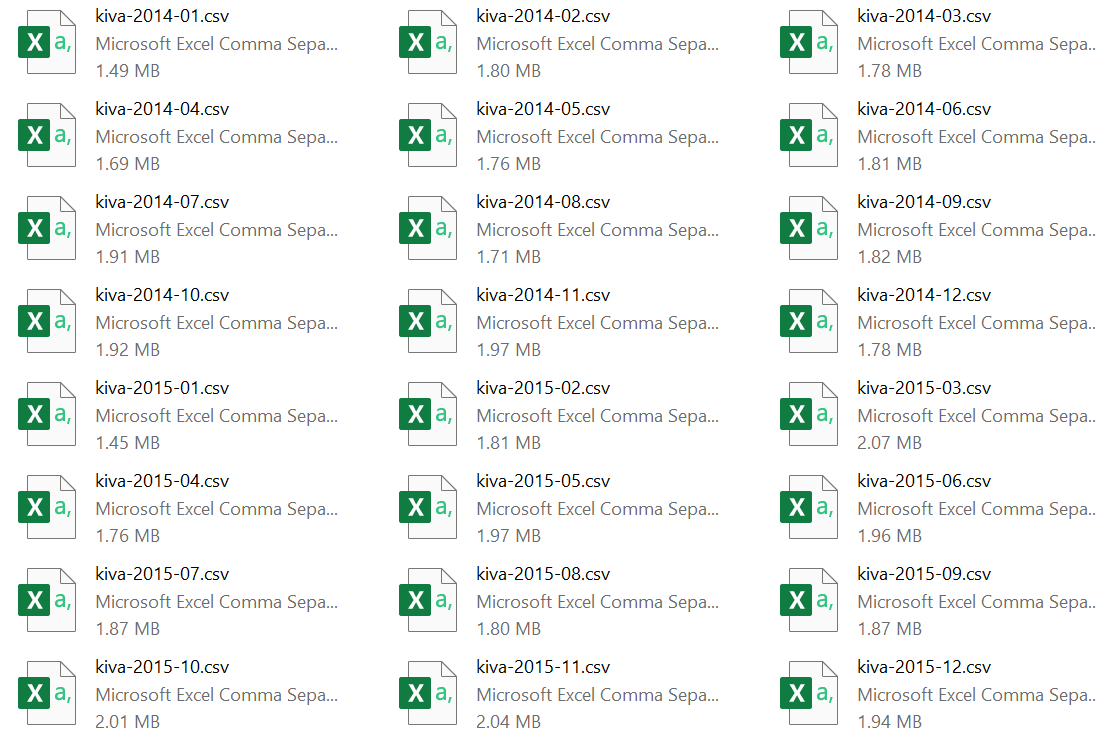
Silahkan cek FOLDERPATH, seharusnya kiva sudah berhasil kita pisahkan menjadi 24 file CSV seperti gambar berikut:
Bagaimana cara menggabungkan beberapa file CSV menjadi satu file CSV?#
Kasus: Kita memiliki 24 file CSV dataset kiva yang dipisahkan berdasarkan periode (tahun-bulan) seperti pada pertanyaan sebelumnya. Kita diminta untuk menggabungkannya menjadi satu file CSV saja untuk kebutuhan analisis.
Maka dari itu, kita perlu tahu semua nama file CSV yang akan kita gabungkan menjadi satu. Caranya, gunakan method glob() kemudian kita spesifikan pola nama file yang ingin diambil. Penggunaan *.csv menandakan kita akan mengambil semua nama file dengan ekstensi csv.
from glob import glob
FOLDERPATH = "data_input/kiva/"
filenames = glob(FOLDERPATH + '*.csv')
filenames
['data_input/kiva/kiva-2014-01.csv',
'data_input/kiva/kiva-2014-02.csv',
'data_input/kiva/kiva-2014-03.csv',
'data_input/kiva/kiva-2014-04.csv',
'data_input/kiva/kiva-2014-05.csv',
'data_input/kiva/kiva-2014-06.csv',
'data_input/kiva/kiva-2014-07.csv',
'data_input/kiva/kiva-2014-08.csv',
'data_input/kiva/kiva-2014-09.csv',
'data_input/kiva/kiva-2014-10.csv',
'data_input/kiva/kiva-2014-11.csv',
'data_input/kiva/kiva-2014-12.csv',
'data_input/kiva/kiva-2015-01.csv',
'data_input/kiva/kiva-2015-02.csv',
'data_input/kiva/kiva-2015-03.csv',
'data_input/kiva/kiva-2015-04.csv',
'data_input/kiva/kiva-2015-05.csv',
'data_input/kiva/kiva-2015-06.csv',
'data_input/kiva/kiva-2015-07.csv',
'data_input/kiva/kiva-2015-08.csv',
'data_input/kiva/kiva-2015-09.csv',
'data_input/kiva/kiva-2015-10.csv',
'data_input/kiva/kiva-2015-11.csv',
'data_input/kiva/kiva-2015-12.csv']
Secara iteratif, baca file CSV menggunakan method .read_csv() kemudian simpan DataFrame ke dalam sebuah list.
df_list = []
for filename in filenames:
df = pd.read_csv(filename)
df_list.append(df)
print(len(df_list))
24
Dengan menggunakan method .concat(), semua DataFrame pada df_list akan digabungkan menjadi satu berdasarkan baris, dengan syarat semua nama kolom harus sama. Method .reset_index() digunakan agar penomoran index diulang dari 0 sampai banyaknya baris pada DataFrame.
kiva_concat = pd.concat(df_list)
kiva_concat = kiva_concat.reset_index(drop=True)
kiva_concat.shape
(323279, 15)
kiva_concat.head()
| year_month | id | funded_amount | loan_amount | activity | sector | country | region | currency | partner_id | posted_time | funded_time | term_in_months | lender_count | repayment_interval | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2014-01 | 653051 | 300.0 | 300.0 | Fruits & Vegetables | Food | Pakistan | Lahore | PKR | 247 | 2014-01-01 06:12:39 | 2014-01-02 10:06:32 | 12 | 12 | irregular |
| 1 | 2014-01 | 653053 | 575.0 | 575.0 | Rickshaw | Transportation | Pakistan | Lahore | PKR | 247 | 2014-01-01 06:51:08 | 2014-01-02 09:17:23 | 11 | 14 | irregular |
| 2 | 2014-01 | 653068 | 150.0 | 150.0 | Transportation | Transportation | India | Maynaguri | INR | 334 | 2014-01-01 09:58:07 | 2014-01-01 16:01:36 | 43 | 6 | bullet |
| 3 | 2014-01 | 653063 | 200.0 | 200.0 | Embroidery | Arts | Pakistan | Lahore | PKR | 247 | 2014-01-01 08:03:11 | 2014-01-01 13:00:00 | 11 | 8 | irregular |
| 4 | 2014-01 | 653084 | 400.0 | 400.0 | Milk Sales | Food | Pakistan | Abdul Hakeem | PKR | 245 | 2014-01-01 11:53:19 | 2014-01-01 19:18:51 | 14 | 16 | monthly |
Simpan objek kiva_concat ke dalam satu file CSV:
kiva_concat.to_csv("data_input/kiva_concat.csv")